Zookeeper框架设计及源码解读
write by valuewithTime, 2021-01-11 21:08引言
从Hadoop的高可用环境,接触到Zookeeper。Zookeeper在高可用集群架构中扮演者重要的角色。除此之外,在微服务盛行的当前,Dubbo默认采用Zookeeper最为注册中心。TBSchedule使用它存储定时任务,控制任务的并发执行。同时Zookeeper作为Raft 一致性协议的经典之作,接下来我们将一探究竟。
目录
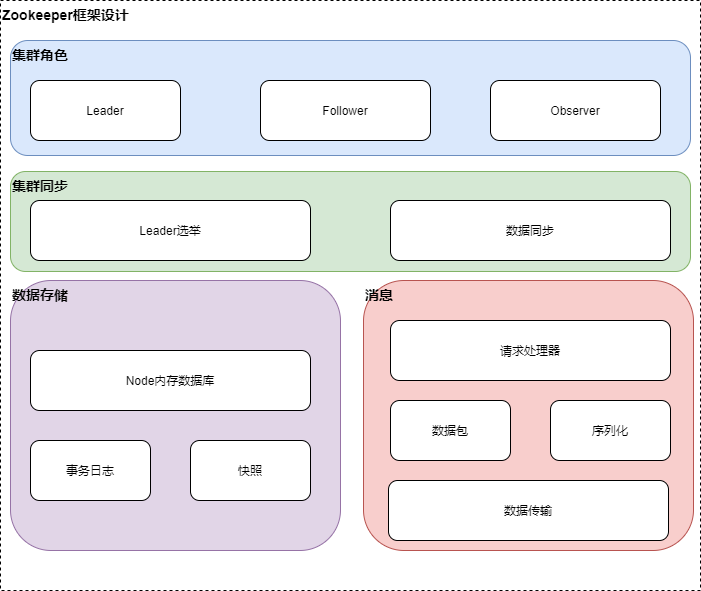
Zookeeper整体架构主要分为数据的存储,消息,leader选举和数据同步这几个模块。leader选举主要是在集群处于混沌的状态下,从集群peer的提议中选择集群的leader,其他为follower或observer,维护集群peer的统一视图,保证整个集群的数据一致性,如果在leader选举成功后,存在follower日志落后的情况,则将事务日志同步给follower。针对消息模块,peer之间的通信包需要序列化和反序列才能发送和处理,具体的消息处理由集群相应角色的消息处理器链来处理。针对客户单的节点的创建,数据修改等操作,将会先写到内存数据库,如果有提交请求,则将数据写到事务日志,同时Zookeeper会定时将内存数据库写到快照日志,以防止没有提交的日志,在宕机的情况下丢失。数据同步模块将leader的事务日志同步给Follower,保证整个集群数据的一致性。
源码分析
源码分析仓库,见 zookeeper github
启动Zookeeper
Zookeeper框架设计及源码解读一(Zookeeper启动)
Zookeeper启动时,首先解析配置文件,根据配置文件选择启动单例还是集群模式。集群模式启动,首先从磁盘中加载数据到内存数据树DataTree, 并添加committed交易日志到DataTree中。然后启动ServerCnxnFactory,监听客户端的请求。实际上是启动了一个基于Netty服务,客户端发送的数据,交由NettyServerCnxn处理,NettyServerCnxn数据包的处理,实际委托给ZooKeeperServer。
Leader选举
Zookeeper框架设计及源码解读二(快速选举策略及选举消息的发送与接收)
启动peer选举策略实际启动的为fast leader 选举策略,如果peer状态为LOOKING, 创建投票(最后提交的日志id,时间戳,peerId)。
fast leader 选举策略启动时实际上启动了一个消息处理器Messenger。 消息处理器内部有一个发送消息工作线程WorkerSender,出列一个需要发送的消息,并把它放入管理器QuorumCnxManager的队列; 一个消息接收线程WorkerReceiver处理从QuorumCnxManager接收的消息。
发送消息工作线程WorkerSender,从FastLeaderElection的发送队列poll消息,并把它放入管理器QuorumCnxManager的队列,如果需要则建立消息关联的peer,并发送协议版本,服务id及选举地址, 如果连接peer的id大于 当前peer的id,则关闭连接,否则启动发送工作线程SendWorker和接收线程RecvWorker。 同时QuorumCnxManager在启动时,启动监听,监听peer的连接。发送消息线程SendWorker,从消息队列拉取消息,并通过Socket的DataOutputStream,发送给peer。
消息接收线程WorkerReceiver从QuorumCnxManager的接收队列中拉取消息,并解析出peer的状态(LOOKING, 观察,Follower,或者leader), 事务id,leaderId,leader选举时间戳,peer的时间戳等信息;如果peer不在当前投票的视图范围之内,同步当前peer的状态(构建通知消息(服务id,事务id,peer状态,时间戳等),并放到发送队列), 然后更新通知(事务id,leaderId,leader选举时间戳,peer时间戳),如果当前peer的状态为LOOKING,则添加通知消息到peer的消息接收队列,如果peer状态为LOOKING,则同步当前节点的投票信息给peer, 若果当前节点为非looker,而peer为looker,则发送当前peer相信的leader信息。
接收工作线程RecvWorker,主要是从Socket的Data输入流中读取数据,并组装成消息,放到QuorumCnxManager的消息接收队列,待消息接收线程WorkerReceiver处理。
LOOKING提议投票阶段
Zookeeper框架设计及源码解读三(leader选举LOOKING阶段)
peer状态有四种LOOKING, OBSERVING,FOLLOWING和LEADING几种状态;LOOKING为初态,Leader还没有选举成功,其他为终态。
当前QuorumPeer处于LOOKING提议投票阶段,启动一个ReadOnlyZooKeeperServer服务,并设置当前peer投票。 ReadOnlyZooKeeperServer内部的处理器链为ReadOnlyRequestProcessor->PrepRequestProcessor->FinalRequestProcessor。 ,只读处理器ReadOnlyRequestProcessor,对CRUD相关的操作,进行忽略,只处理check请求,并通过NettyServerCnxn发送ReplyHeader,头部主要的信息为内存数据库的最大事务id。
创建投票,首先更新当前的投票信息,如果peer为参与者,首先投自己一票(当前peer的serverId,最大事务id,以及时间戳),并发送通知到所有投票peer; 如果peer状态为LOOKING,且选举没有结束,则从接收消息队列拉取通知, 如果通知为空,则发送投票提议通知到所有投票peer, 否则判断下一轮投票视图是否包括当前通知的server和提议leader, 则判断peer的状态(LOOKING,OBSERVING,FOLLOWING,LEADING)。当前peer状态为LOOKING时,,如果通知的时间点,大于当前server时间点,则更新投票提议,并发送通知消息到所有投票peer。如果当前节点的Quorum Peer都进行投票回复,然后从接收队列中拉取通知投票消息,如果为空,则投票结束,更新当前投票状态为LEADING。当peer为OBSERVING,FOLLOWING状态,什么都不做;当peer状态为leading,则如果投票的时间戳和当前节点的投票时间戳一致,并且所有peer都回复,则结束投票。
OBSERVING观察者同步leader
Zookeeper框架设计及源码解读四(观察者观察leader)
观察者同步leader,首先从输入流中读取数据包,如果是快照同步,则从leader同步快照信息,并添加DataTree;如果是TUNC命令,则截取日志(观察者日志快于Leader),然后从磁盘中加载数据到内存数据树DataTree, 并添加committed交易日志到DataTree中。如果观察者节点没有启动,则启动ZookeeperServer(ObserverZooKeeperServer,FollowerZooKeeperServer,LeaderZooKeeperServer),并设置消息处理器链,更新启动状态,然后更新选举时间戳;如果server为FollowerZooKeeperServer,则log请求未提交的请求,并添加到请求队列,同时唤起syncProcessor处理请求,针对已提交的请求,交由commitProcessor处理。如果是ObserverZooKeeperServer,则只处理为提交的请求,交由commitProcessor处理。如果Server已经启动,针对重新选举这种情形,从输入流中读取消息,如果是提议消息,则添加到未提交消息队列;如果是为提交消息,则从待提交队列,拉取消息,并添加到提交消息队列。如果为通知消息,针对没有写到日志的情形,则委托server处理请求,否则将消息添加待提交和提交消息队列。如果为UPTODATE消息,则leader通知follower ,可以响应客户端的请求,如果需要则拍摄快照,并跟新选举时间戳。如果为NEWLEADER请求,则更新选举时间戳,发送回复消息,如果需要拍摄快照,则takeSnapshot。观察者,只处理ping,同步,及通知请求。
FOLLOWING跟随者状态
LEADING领导者状态
Zookeeper框架设计及源码解读五(跟随者状态、领导者状态)
跟随者,跟随领导者首先连接leader,注册follower状态,在leader连接的过程中,如果发现消息队列中有LEADERINFO请求,则响应leader然后同步leader,这部分逻辑和观察者一致,主要有同步leader日志快照,如果为TUNC命令,则截取事务日志。
跟随者处理消息包,如果为提议消息,则log请求,提交消息,则委托给commit处理器处理,如果为同步请求则从同步请求队列拉取消息,并委托给commit处理器处理。
领导者首先加载数据到内存数据库,创建新leader数据包,然后等待所有Quorum, peer 全部投票完毕, 启动server(LeaderZooKeeperServer)。
节点状态的确定逻辑为集群没有配置,则为LOOING状态,如果节点投注的serverId为当前节点,则为Leader,如果学习的类型为参与者,则为节点状态为跟踪者,如果学习类型为观察状态,则为观察者。
消息处理
Leader消息处理
Zookeeper框架设计及源码解读六(Leader消息处理)
观察者、跟随者、和领导者启动server,分别为,LeaderZooKeeperServer,FollowerZooKeeperServer,ObserverZooKeeperServer. Leader的消息处处理器链为LeaderRequestProcessor->PrepRequestProcessor->ProposalRequestProcessor->CommitProcessor->ToBeAppliedRequestProcessor->FinalRequestProcessor; Follower的消息处理器链为SendAckRequestProcessor->SyncRequestProcessor->FollowerRequestProcessor->CommitProcessor->FinalRequestProcessor. Observer的消息处处理器链为SyncRequestProcessor->ObserverRequestProcessor->CommitProcessor->FinalRequestProcessor;
LeaderRequestProcessor处理器主要做的本地会话检查,并更新会话保活信息。 PrepRequestProcessor处理消息,首先添加到内部的提交请求队列,然后启动线程预处理请求。 预处理消息,主要是针对事务性的CUD, 则构建响应的请求,比如CreateRequest,SetDataRequest等。针对非事务性R,则检查会话的有效性。 事务性预处理请求,主要是将请求包装成事件变更记录ZooKeeperServer,并保存到Zookeeper的请求变更记录集outstandingChanges中。 ProposalRequestProcessor处理器,主要处理同步请求消息,针对同步请求,则发送消息到响应的server。 CommitProcessor,主要是过滤出需要提交的请求,比如CRUD等,并交由下一个处理器处理。 ToBeAppliedRequestProcessor处理器,主要是保证提议为最新。 FinalRequestProcessor首先由ZooKeeperServer处理CUD相关的请求操作,针对R类的相关操作,直接查询ZooKeeperServer的内存数据库。 ZooKeeperServer处理CUD操作,委托表给ZKDatabase,ZKDatabase委托给DataTree, DataTree根据CUD相关请求操作,CUD相应路径的 DataNode。针对R类操作,获取dataTree的DataNode的相关信息。
Follower消息处理
Observer消息处理
Zookeeper框架设计及源码解读七(跟随者观察者消息处理器)
针对跟随者,SendAckRequestProcessor处理器,针对非同步操作,回复ACK。 SyncRequestProcessor处理器从请求队列拉取请求,针对刷新队列不为空的情况,如果请求队列为空,则提交请求日志,并刷新到磁盘,否则根据日志计数器和快照计数器计算是否需要拍摄快照。 FollowerRequestProcessor处理器,从请求队列拉取请求,如果请求为同步请求,则添加请求到同步队列, 并转发请求给leader,如果为CRUD相关的操作,直接转发请求给leader。
针对观察者,观察者请求处理器,从请求队列拉取请求,如果请求为同步请求,则添加请求到同步队列, 并转发请求给leader,如果为CRUD相关的操作,直接转发请求给leader。
数据存储
ZK数据库ZKDatabase主要有数据树DataTree和文件快照日志FileTxnSnapLog。 事务日志添加,提交,回滚,截断,委托给文件快照日志FileTxnSnapLog。 请求处理,获取节点数据,委托给有数据树DataTree。 交易快照日志FileTxnSnapLog有两部分组成一个是已提交的事务日志文件目录dataDir,快照日志文件目录snapDir组成。 事务日志txnLog对应的为FileTxnLog, 快照日志snapLog为FileSnap。
提交事务实际,实际为将文件输出流,刷新磁盘(事务日志文件目录)。 回滚事务日志,实际为重置日志流logStream为BufferedOutputStream为null。 截断日志,实际为根据事务zxid, 删除大于zxid的事务日志文件。 拍摄快照,实际为将DataTree,序列化到快照日志文件。
DataTree主要是通过节点HashMap来维护节点信息(ConcurrentHashMap<String, DataNode>())。
数据DataNode有一个字节数组(byte data[])存储数据,Set