Zookeeper框架设计及源码解读三(leader选举LOOKING阶段)
write by valuewithTime, 2020-12-23 21:09引言
启动peer选举策略实际启动的为fast leader 选举策略,如果peer状态为LOOKING, 创建投票(最后提交的日志id,时间戳,peerId)。
fast leader 选举策略启动时实际上启动了一个消息处理器Messenger。 消息处理器内部有一个发送消息工作线程WorkerSender,出列一个需要发送的消息,并把它放入管理器QuorumCnxManager的队列; 一个消息接收线程WorkerReceiver处理从QuorumCnxManager接收的消息。
发送消息工作线程WorkerSender,从FastLeaderElection的发送队列poll消息,并把它放入管理器QuorumCnxManager的队列,如果需要则建立消息关联的peer,并发送协议版本,服务id及选举地址, 如果连接peer的id大于 当前peer的id,则关闭连接,否则启动发送工作线程SendWorker和接收线程RecvWorker。 同时QuorumCnxManager在启动时,启动监听,监听peer的连接。发送消息线程SendWorker,从消息队列拉取消息,并通过Socket的DataOutputStream,发送给peer。
消息接收线程WorkerReceiver从QuorumCnxManager的接收队列中拉取消息,并解析出peer的状态(LOOKING, 观察,Follower,或者leader), 事务id,leaderId,leader选举时间戳,peer的时间戳等信息;如果peer不在当前投票的视图范围之内,同步当前peer的状态(构建通知消息(服务id,事务id,peer状态,时间戳等),并放到发送队列), 然后更新通知(事务id,leaderId,leader选举时间戳,peer时间戳),如果当前peer的状态为LOOKING,则添加通知消息到peer的消息接收队列,如果peer状态为LOOKING,则同步当前节点的投票信息给peer, 若果当前节点为非looker,而peer为looker,则发送当前peer相信的leader信息。
接收工作线程RecvWorker,主要是从Socket的Data输入流中读取数据,并组装成消息,放到QuorumCnxManager的消息接收队列,待消息接收线程WorkerReceiver处理。
这是我们上一篇讲的快速选举策略,具体peer对选举策略如何处理,这是我们今天需要讲的内容。
目录
概要框架设计
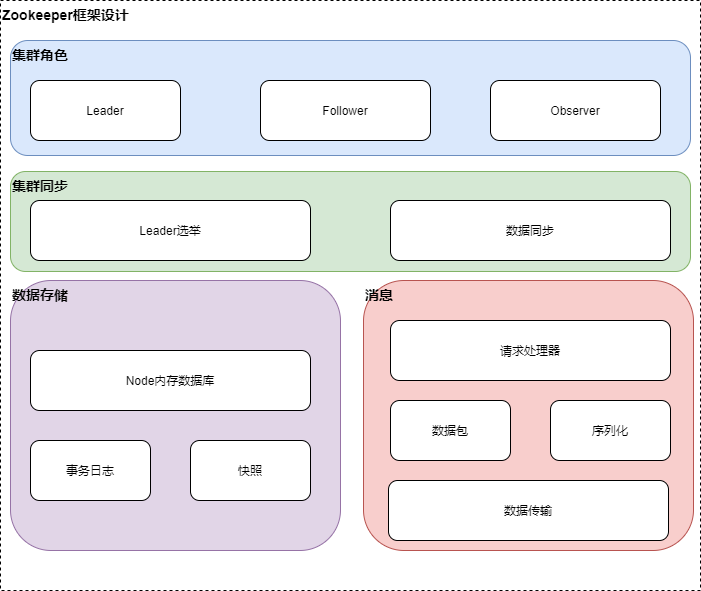
Zookeeper整体架构主要分为数据的存储,消息,leader选举和数据同步这几个模块。leader选举主要是在集群处于混沌的状态下,从集群peer的提议中选择集群的leader,其他为follower或observer,维护集群peer的统一视图,保证整个集群的数据一致性,如果在leader选举成功后,存在follower日志落后的情况,则将事务日志同步给follower。针对消息模块,peer之间的通信包需要序列化和反序列才能发送和处理,具体的消息处理由集群相应角色的消息处理器链来处理。针对客户单的节点的创建,数据修改等操作,将会先写到内存数据库,如果有提交请求,则将数据写到事务日志,同时Zookeeper会定时将内存数据库写到快照日志,以防止没有提交的日志,在宕机的情况下丢失。数据同步模块将leader的事务日志同步给Follower,保证整个集群数据的一致性。
源码分析
源码分析仓库,见 zookeeper github
启动Zookeeper
Zookeeper框架设计及源码解读一(Zookeeper启动)
Leader选举
Zookeeper框架设计及源码解读二(快速选举策略及选举消息的发送与接收)
QuorumPeer选举机制及处理策略
//
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider {
private static final Logger LOG = LoggerFactory.getLogger(QuorumPeer.class);
private QuorumBean jmxQuorumBean;
LocalPeerBean jmxLocalPeerBean;
private Map<Long, RemotePeerBean> jmxRemotePeerBean;
LeaderElectionBean jmxLeaderElectionBean;
private QuorumCnxManager qcm;
QuorumAuthServer authServer;
QuorumAuthLearner authLearner;
/**
* ZKDatabase is a top level member of quorumpeer
* which will be used in all the zookeeperservers
* instantiated later. Also, it is created once on
* bootup and only thrown away in case of a truncate
* message from the leader
*/
private ZKDatabase zkDb;
...
@Override
public void run() {
updateThreadName();
...
try {
/*
* Main loop
*/
while (running) {
switch (getPeerState()) {
case LOOKING:
//LOOKING 阶段
LOG.info("LOOKING");
if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately 只读ZookeeperServer
final ReadOnlyZooKeeperServer roZk =
new ReadOnlyZooKeeperServer(logFactory, this, this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
//如果是LOOKING 状态,则启动只读zk server
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
//开启leader选举
startLeaderElection();
}
//设置当前投票
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
//观察节点
try {
LOG.info("OBSERVING");
//org.apache.zookeeper.server.quorum.Observer
//org.apache.zookeeper.server.quorum.ObserverZooKeeperServer
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e );
} finally {
observer.shutdown();
setObserver(null);
updateServerState();
}
break;
case FOLLOWING:
//跟随者
try {
LOG.info("FOLLOWING");
//org.apache.zookeeper.server.quorum.Follower
//org.apache.zookeeper.server.quorum.FollowerZooKeeperServer
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
updateServerState();
}
break;
case LEADING:
//Leader
LOG.info("LEADING");
try {
//org.apache.zookeeper.server.quorum.Learner
//org.apache.zookeeper.server.quorum.LearnerZooKeeperServer
setLeader(makeLeader(logFactory));
//lead
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
updateServerState();
}
break;
}
start_fle = Time.currentElapsedTime();
}
} finally {
LOG.warn("QuorumPeer main thread exited");
MBeanRegistry instance = MBeanRegistry.getInstance();
instance.unregister(jmxQuorumBean);
instance.unregister(jmxLocalPeerBean);
for (RemotePeerBean remotePeerBean : jmxRemotePeerBean.values()) {
instance.unregister(remotePeerBean);
}
jmxQuorumBean = null;
jmxLocalPeerBean = null;
jmxRemotePeerBean = null;
}
}
...
}
从上面可以看出,peer状态有四种LOOKING, OBSERVING,FOLLOWING和LEADING几种状态;LOOKING为初态,Leader还没有选举成功,其他为终态。下面我们分别来看四种终态
- LOOKING提议投票阶段
- OBSERVING观察者状态
- FOLLOWING跟随者状态
- LEADING领导者状态
LOOKING提议投票阶段
//QuorumPeer
//LOOKING 阶段
LOG.info("LOOKING");
if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately 只读ZookeeperServer
final ReadOnlyZooKeeperServer roZk =
new ReadOnlyZooKeeperServer(logFactory, this, this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
//如果是LOOKING 状态,则启动只读zk server
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
//开启leader选举
startLeaderElection();
}
//设置当前投票
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
当前QuorumPeer处于LOOKING提议投票阶段,启动一个ReadOnlyZooKeeperServer服务,并设置当前peer投票。
分别来看上面关键的两部。
//ReadOnlyZooKeeperServer
public class ReadOnlyZooKeeperServer extends ZooKeeperServer {
protected final QuorumPeer self;
private volatile boolean shutdown = false;
...
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor prepProcessor = new PrepRequestProcessor(this, finalProcessor);
((PrepRequestProcessor) prepProcessor).start();
firstProcessor = new ReadOnlyRequestProcessor(this, prepProcessor);
((ReadOnlyRequestProcessor) firstProcessor).start();
}
@Override
public synchronized void startup() {
// check to avoid startup follows shutdown
if (shutdown) {
LOG.warn("Not starting Read-only server as startup follows shutdown!");
return;
}
registerJMX(new ReadOnlyBean(this), self.jmxLocalPeerBean);
super.startup();
self.setZooKeeperServer(this);
self.adminServer.setZooKeeperServer(this);
LOG.info("Read-only server started");
}
...
}
ReadOnlyZooKeeperServer内部的处理器链为ReadOnlyRequestProcessor->PrepRequestProcessor->FinalRequestProcessor。
//ReadOnlyRequestProcessor
public class ReadOnlyRequestProcessor extends ZooKeeperCriticalThread implements
RequestProcessor {
private static final Logger LOG = LoggerFactory.getLogger(ReadOnlyRequestProcessor.class);
/**
* 请求队列
*/
private final LinkedBlockingQueue<Request> queuedRequests = new LinkedBlockingQueue<Request>();
private boolean finished = false;
private final RequestProcessor nextProcessor;
private final ZooKeeperServer zks;
public ReadOnlyRequestProcessor(ZooKeeperServer zks,
RequestProcessor nextProcessor) {
super("ReadOnlyRequestProcessor:" + zks.getServerId(), zks
.getZooKeeperServerListener());
this.zks = zks;
this.nextProcessor = nextProcessor;
}
public void run() {
try {
while (!finished) {
Request request = queuedRequests.take();
// log request
long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK;
if (request.type == OpCode.ping) {
traceMask = ZooTrace.CLIENT_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, traceMask, 'R', request, "");
}
if (Request.requestOfDeath == request) {
break;
}
// filter read requests 过滤器读请求
switch (request.type) {
case OpCode.sync:
case OpCode.create:
case OpCode.create2:
case OpCode.createTTL:
case OpCode.createContainer:
case OpCode.delete:
case OpCode.deleteContainer:
case OpCode.setData:
case OpCode.reconfig:
case OpCode.setACL:
case OpCode.multi:
case OpCode.check:
ReplyHeader hdr = new ReplyHeader(request.cxid, zks.getZKDatabase()
.getDataTreeLastProcessedZxid(), Code.NOTREADONLY.intValue());
try {
request.cnxn.sendResponse(hdr, null, null);
} catch (IOException e) {
LOG.error("IO exception while sending response", e);
}
continue;
}
// proceed to the next processor
if (nextProcessor != null) {
nextProcessor.processRequest(request);
}
}
} catch (RequestProcessorException e) {
if (e.getCause() instanceof XidRolloverException) {
LOG.info(e.getCause().getMessage());
}
handleException(this.getName(), e);
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("ReadOnlyRequestProcessor exited loop!");
}
@Override
public void processRequest(Request request) {
if (!finished) {
queuedRequests.add(request);
}
}
@Override
public void shutdown() {
finished = true;
queuedRequests.clear();
queuedRequests.add(Request.requestOfDeath);
nextProcessor.shutdown();
}
}
从上面可以看出,只读处理器,对CRUD相关的操作,进行忽略,只处理check请求,并通过NettyServerCnxn发送ReplyHeader,头部主要的信息为内存数据库的最大事务id。
再来看peer投票
//QuorumPeer
protected Election makeLEStrategy(){
LOG.debug("Initializing leader election protocol...");
return electionAlg;
}
//FastLeaderElection
/**
* Starts a new round of leader election. Whenever our QuorumPeer
* changes its state to LOOKING, this method is invoked, and it
* sends notifications to all other peers.
* 开启新的一轮leader选举。当QuorumPeer改变他的状态为LOOKING时,此方法,将会触发
* ,并发送通知到其他Peer
*/
public Vote lookForLeader() throws InterruptedException {
try {
self.jmxLeaderElectionBean = new LeaderElectionBean();
MBeanRegistry.getInstance().register(
self.jmxLeaderElectionBean, self.jmxLocalPeerBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
self.jmxLeaderElectionBean = null;
}
if (self.start_fle == 0) {
self.start_fle = Time.currentElapsedTime();
}
try {
//接收投票集
Map<Long, Vote> recvset = new HashMap<Long, Vote>();
Map<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
synchronized(this){
logicalclock.incrementAndGet();
//更新leader提议
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
LOG.info("New election. My id = " + self.getId() +
", proposed zxid=0x" + Long.toHexString(proposedZxid));
//发送通知到所有投票peer
sendNotifications();
/*
* Loop in which we exchange notifications until we find a leader
* 交换通知循环,知道发现leader
*/
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
/*
* Remove next notification from queue, times out after 2 times
* the termination time
* 如果为LOOKING, 且没有停止,从接收消息队列拉取通知
*/
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
/*
* Sends more notifications if haven't received enough.
* Otherwise processes new notification.
*/
if(n == null){
if(manager.haveDelivered()){
//为空则发送通知
sendNotifications();
} else {
//连接所有投票peer
manager.connectAll();
}
/*
* Exponential backoff
*/
int tmpTimeOut = notTimeout*2;
notTimeout = (tmpTimeOut < maxNotificationInterval?
tmpTimeOut : maxNotificationInterval);
LOG.info("Notification time out: " + notTimeout);
}
else if (validVoter(n.sid) && validVoter(n.leader)) {
//当前下一轮投票视图包括当前server和提议leader
/*
* Only proceed if the vote comes from a replica in the current or next
* voting view for a replica in the current or next voting view.
*/
switch (n.state) {
case LOOKING:
if (getInitLastLoggedZxid() == -1) {
LOG.debug("Ignoring notification as our zxid is -1");
break;
}
if (n.zxid == -1) {
LOG.debug("Ignoring notification from member with -1 zxid" + n.sid);
break;
}
// If notification > current, replace and send messages out
//如果通知的时间点,大于当前server时间点,则替换,并发送通知消息
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
if(LOG.isDebugEnabled()){
LOG.debug("Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x"
+ Long.toHexString(n.electionEpoch)
+ ", logicalclock=0x" + Long.toHexString(logicalclock.get()));
}
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
if(LOG.isDebugEnabled()){
LOG.debug("Adding vote: from=" + n.sid +
", proposed leader=" + n.leader +
", proposed zxid=0x" + Long.toHexString(n.zxid) +
", proposed election epoch=0x" + Long.toHexString(n.electionEpoch));
}
//接收peer投票
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//所有quorum节点都进行了回复
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
//从接收队列拉取消息,确认leader提议没有变
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new
* relevant message from the reception queue
*/
if (n == null) {
//如果为leader为当前节点,则更新节点状态为leader,否learning 状态,跟随者或观察者
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid, proposedEpoch);
//leader选举结束
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
LOG.debug("Notification from observer: " + n.sid);
break;
case FOLLOWING:
case LEADING:
//处理leader通知
/*
* Consider all notifications from the same epoch
* together.
*/
if(n.electionEpoch == logicalclock.get()){
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
if(termPredicate(recvset, new Vote(n.leader,
n.zxid, n.electionEpoch, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, n.electionEpoch)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
/*
* Before joining an established ensemble, verify that
* a majority are following the same leader.
* Only peer epoch is used to check that the votes come
* from the same ensemble. This is because there is at
* least one corner case in which the ensemble can be
* created with inconsistent zxid and election epoch
* info. However, given that only one ensemble can be
* running at a single point in time and that each
* epoch is used only once, using only the epoch to
* compare the votes is sufficient.
*
* 在加入一个已经建立的共识之前,验证大多数跟谁同一个leader。
* peer的时间点epoch,用于检查投票来自于同一个一时间点;
* 避免产生不同的zxid和选举时间点。
*
*
* @see https://issues.apache.org/jira/browse/ZOOKEEPER-1732
*
*
*/
outofelection.put(n.sid, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state));
if (termPredicate(outofelection, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, IGNOREVALUE)) {
synchronized(this){
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
LOG.warn("Notification state unrecoginized: " + n.state
+ " (n.state), " + n.sid + " (n.sid)");
break;
}
} else {
if (!validVoter(n.leader)) {
LOG.warn("Ignoring notification for non-cluster member sid {} from sid {}", n.leader, n.sid);
}
if (!validVoter(n.sid)) {
LOG.warn("Ignoring notification for sid {} from non-quorum member sid {}", n.leader, n.sid);
}
}
}
return null;
} finally {
try {
if(self.jmxLeaderElectionBean != null){
MBeanRegistry.getInstance().unregister(
self.jmxLeaderElectionBean);
}
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
self.jmxLeaderElectionBean = null;
LOG.debug("Number of connection processing threads: {}",
manager.getConnectionThreadCount());
}
}
从上面可以看出, 创建投票,首先更新当前的投票信息,如果peer为参与者,首先投自己一票(当前peer的serverId,最大事务id,以及时间戳),并发送通知到所有投票peer; 如果peer状态为LOOKING,且选举没有结束,则从接收消息队列拉取通知, 如果通知为空,则发送投票提议通知到所有投票peer, 否则判断下一轮投票视图是否包括当前通知的server和提议leader, 则判断peer的状态(LOOKING,OBSERVING,FOLLOWING,LEADING)。当前peer状态为LOOKING时,,如果通知的时间点,大于当前server时间点,则更新投票提议,并发送通知消息到所有投票peer。如果当前节点的Quorum Peer都进行投票回复,然后从接收队列中拉取通知投票消息,如果为空,则投票结束,更新当前投票状态为LEADING。当peer为OBSERVING,FOLLOWING状态,什么都不做;当peer状态为leading,则如果投票的时间戳和当前节点的投票时间戳一致,并且所有peer都回复,则结束投票。
这里有一个疑问,理论上,不是2/3选举通过就行了吗,为什么是所有投票peer产生共识,难道是我拉去代码的原因。
小节
当前QuorumPeer处于LOOKING提议投票阶段,启动一个ReadOnlyZooKeeperServer服务,并设置当前peer投票。 ReadOnlyZooKeeperServer内部的处理器链为ReadOnlyRequestProcessor->PrepRequestProcessor->FinalRequestProcessor。 ,只读处理器ReadOnlyRequestProcessor,对CRUD相关的操作,进行忽略,只处理check请求,并通过NettyServerCnxn发送ReplyHeader,头部主要的信息为内存数据库的最大事务id。
创建投票,首先更新当前的投票信息,如果peer为参与者,首先投自己一票(当前peer的serverId,最大事务id,以及时间戳),并发送通知到所有投票peer; 如果peer状态为LOOKING,且选举没有结束,则从接收消息队列拉取通知, 如果通知为空,则发送投票提议通知到所有投票peer, 否则判断下一轮投票视图是否包括当前通知的server和提议leader, 则判断peer的状态(LOOKING,OBSERVING,FOLLOWING,LEADING)。当前peer状态为LOOKING时,,如果通知的时间点,大于当前server时间点,则更新投票提议,并发送通知消息到所有投票peer。如果当前节点的Quorum Peer都进行投票回复,然后从接收队列中拉取通知投票消息,如果为空,则投票结束,更新当前投票状态为LEADING。当peer为OBSERVING,FOLLOWING状态,什么都不做;当peer状态为leading,则如果投票的时间戳和当前节点的投票时间戳一致,并且所有peer都回复,则结束投票。
后面几种状态,限于篇幅,我们放到后面再讲
OBSERVING观察者状态
//QuorumPeer
//观察节点
try {
LOG.info("OBSERVING");
//org.apache.zookeeper.server.quorum.Observer
//org.apache.zookeeper.server.quorum.ObserverZooKeeperServer
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e );
} finally {
observer.shutdown();
setObserver(null);
updateServerState();
}
FOLLOWING跟随者状态
//QuorumPeer
try {
LOG.info("FOLLOWING");
//org.apache.zookeeper.server.quorum.Follower
//org.apache.zookeeper.server.quorum.FollowerZooKeeperServer
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
updateServerState();
}
LEADING领导者状态
//QuorumPeer
try {
//org.apache.zookeeper.server.quorum.Learner
//org.apache.zookeeper.server.quorum.LearnerZooKeeperServer
setLeader(makeLeader(logFactory));
//lead
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
updateServerState();
}
总结
peer状态有四种LOOKING, OBSERVING,FOLLOWING和LEADING几种状态;LOOKING为初态,Leader还没有选举成功,其他为终态。
当前QuorumPeer处于LOOKING提议投票阶段,启动一个ReadOnlyZooKeeperServer服务,并设置当前peer投票。 ReadOnlyZooKeeperServer内部的处理器链为ReadOnlyRequestProcessor->PrepRequestProcessor->FinalRequestProcessor。 ,只读处理器ReadOnlyRequestProcessor,对CRUD相关的操作,进行忽略,只处理check请求,并通过NettyServerCnxn发送ReplyHeader,头部主要的信息为内存数据库的最大事务id。
创建投票,首先更新当前的投票信息,如果peer为参与者,首先投自己一票(当前peer的serverId,最大事务id,以及时间戳),并发送通知到所有投票peer; 如果peer状态为LOOKING,且选举没有结束,则从接收消息队列拉取通知, 如果通知为空,则发送投票提议通知到所有投票peer, 否则判断下一轮投票视图是否包括当前通知的server和提议leader, 则判断peer的状态(LOOKING,OBSERVING,FOLLOWING,LEADING)。当前peer状态为LOOKING时,,如果通知的时间点,大于当前server时间点,则更新投票提议,并发送通知消息到所有投票peer。如果当前节点的Quorum Peer都进行投票回复,然后从接收队列中拉取通知投票消息,如果为空,则投票结束,更新当前投票状态为LEADING。当peer为OBSERVING,FOLLOWING状态,什么都不做;当peer状态为leading,则如果投票的时间戳和当前节点的投票时间戳一致,并且所有peer都回复,则结束投票。