Zookeeper框架设计及源码解读五(跟随者状态、领导者状态)
write by valuewithTime, 2020-12-30 19:53引言
观察者同步leader,首先从输入流中读取数据包,如果是快照同步,则从leader同步快照信息,并添加DataTree;如果是TUNC命令,则截取日志(观察者日志快于Leader),然后从磁盘中加载数据到内存数据树DataTree, 并添加committed交易日志到DataTree中。如果观察者节点没有启动,则启动ZookeeperServer(ObserverZooKeeperServer,FollowerZooKeeperServer,LeaderZooKeeperServer),并设置消息处理器链,更新启动状态,然后更新选举时间戳;如果server为FollowerZooKeeperServer,则log请求未提交的请求,并添加到请求队列,同时唤起syncProcessor处理请求,针对已提交的请求,交由commitProcessor处理。如果是ObserverZooKeeperServer,则只处理为提交的请求,交由commitProcessor处理。如果Server已经启动,针对重新选举这种情形,从输入流中读取消息,如果是提议消息,则添加到未提交消息队列;如果是为提交消息,则从待提交队列,拉取消息,并添加到提交消息队列。如果为通知消息,针对没有写到日志的情形,则委托server处理请求,否则将消息添加待提交和提交消息队列。如果为UPTODATE消息,则leader通知follower ,可以响应客户端的请求,如果需要则拍摄快照,并跟新选举时间戳。如果为NEWLEADER请求,则更新选举时间戳,发送回复消息,如果需要拍摄快照,则takeSnapshot。观察者,只处理ping,同步,及通知请求。
上一篇,我们看了观察者同步leader,今天我们来看一下跟随者相关的选举逻辑。
目录
概要框架设计
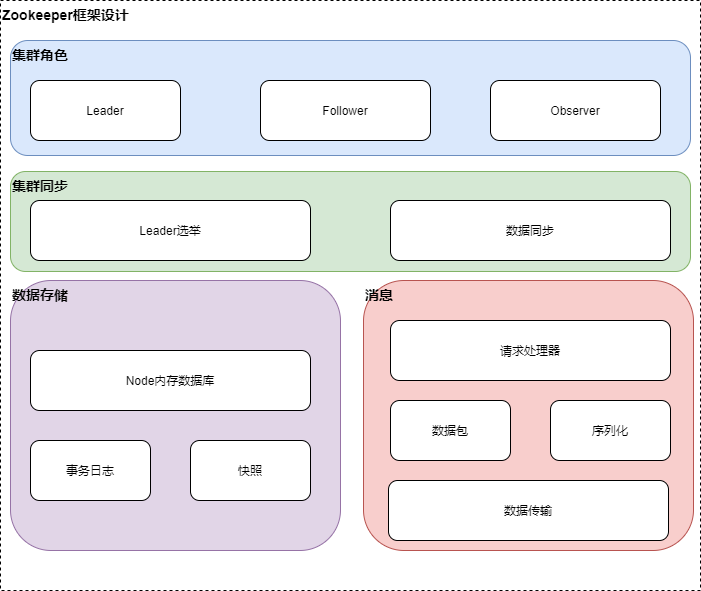
Zookeeper整体架构主要分为数据的存储,消息,leader选举和数据同步这几个模块。leader选举主要是在集群处于混沌的状态下,从集群peer的提议中选择集群的leader,其他为follower或observer,维护集群peer的统一视图,保证整个集群的数据一致性,如果在leader选举成功后,存在follower日志落后的情况,则将事务日志同步给follower。针对消息模块,peer之间的通信包需要序列化和反序列才能发送和处理,具体的消息处理由集群相应角色的消息处理器链来处理。针对客户单的节点的创建,数据修改等操作,将会先写到内存数据库,如果有提交请求,则将数据写到事务日志,同时Zookeeper会定时将内存数据库写到快照日志,以防止没有提交的日志,在宕机的情况下丢失。数据同步模块将leader的事务日志同步给Follower,保证整个集群数据的一致性。
源码分析
源码分析仓库,见 zookeeper github
启动Zookeeper
Zookeeper框架设计及源码解读一(Zookeeper启动)
Leader选举
Zookeeper框架设计及源码解读二(快速选举策略及选举消息的发送与接收)
LOOKING提议投票阶段
Zookeeper框架设计及源码解读三(leader选举LOOKING阶段)
OBSERVING观察者同步leader
Zookeeper框架设计及源码解读四(观察者观察leader)
跟随者follow领导者
case FOLLOWING:
//跟随者
try {
LOG.info("FOLLOWING");
//org.apache.zookeeper.server.quorum.Follower
//org.apache.zookeeper.server.quorum.FollowerZooKeeperServer
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
updateServerState();
}
break;
来看一下follow 领导者
public class Follower extends Learner{
private long lastQueued;
/**
* This is the same object as this.zk, but we cache the downcast op
*/
final FollowerZooKeeperServer fzk;
Follower(QuorumPeer self,FollowerZooKeeperServer zk) {
this.self = self;
this.zk=zk;
this.fzk = zk;
}
...
/**
* the main method called by the follower to follow the leader
* 跟随leader操作
*
* @throws InterruptedException
*/
void followLeader() throws InterruptedException {
self.end_fle = Time.currentElapsedTime();
long electionTimeTaken = self.end_fle - self.start_fle;
self.setElectionTimeTaken(electionTimeTaken);
LOG.info("FOLLOWING - LEADER ELECTION TOOK - {} {}", electionTimeTaken,
QuorumPeer.FLE_TIME_UNIT);
self.start_fle = 0;
self.end_fle = 0;
fzk.registerJMX(new FollowerBean(this, zk), self.jmxLocalPeerBean);
try {
QuorumServer leaderServer = findLeader();
try {
connectToLeader(leaderServer.addr, leaderServer.hostname);
long newEpochZxid = registerWithLeader(Leader.FOLLOWERINFO);
if (self.isReconfigStateChange())
throw new Exception("learned about role change");
//check to see if the leader zxid is lower than ours
//this should never happen but is just a safety check
long newEpoch = ZxidUtils.getEpochFromZxid(newEpochZxid);
if (newEpoch < self.getAcceptedEpoch()) {
LOG.error("Proposed leader epoch " + ZxidUtils.zxidToString(newEpochZxid)
+ " is less than our accepted epoch " + ZxidUtils.zxidToString(self.getAcceptedEpoch()));
throw new IOException("Error: Epoch of leader is lower");
}
syncWithLeader(newEpochZxid);
QuorumPacket qp = new QuorumPacket();
while (this.isRunning()) {
readPacket(qp);
//处理器出举报
processPacket(qp);
}
} catch (Exception e) {
LOG.warn("Exception when following the leader", e);
try {
sock.close();
} catch (IOException e1) {
e1.printStackTrace();
}
// clear pending revalidations
pendingRevalidations.clear();
}
} finally {
zk.unregisterJMX((Learner)this);
}
}
...
}
跟随者,跟随领导者首先连接leader,注册follower状态,在leader连接的过程中,如果发现消息队列中有LEADERINFO请求,则响应leader然后同步leader,这部分逻辑和观察者一致,主要有同步leader日志快照,如果为TUNC命令,则截取事务日志。
再来看一下消息处理
/**
* Examine the packet received in qp and dispatch based on its contents.
* @param qp
* @throws IOException
*/
protected void processPacket(QuorumPacket qp) throws Exception{
switch (qp.getType()) {
case Leader.PING:
ping(qp);
break;
case Leader.PROPOSAL:
//提议
TxnHeader hdr = new TxnHeader();
Record txn = SerializeUtils.deserializeTxn(qp.getData(), hdr);
if (hdr.getZxid() != lastQueued + 1) {
LOG.warn("Got zxid 0x"
+ Long.toHexString(hdr.getZxid())
+ " expected 0x"
+ Long.toHexString(lastQueued + 1));
}
lastQueued = hdr.getZxid();
if (hdr.getType() == OpCode.reconfig){
SetDataTxn setDataTxn = (SetDataTxn) txn;
QuorumVerifier qv = self.configFromString(new String(setDataTxn.getData()));
self.setLastSeenQuorumVerifier(qv, true);
}
fzk.logRequest(hdr, txn);
break;
case Leader.COMMIT:
//提交协议
fzk.commit(qp.getZxid());
break;
case Leader.COMMITANDACTIVATE:
// get the new configuration from the request
Request request = fzk.pendingTxns.element();
SetDataTxn setDataTxn = (SetDataTxn) request.getTxn();
QuorumVerifier qv = self.configFromString(new String(setDataTxn.getData()));
// get new designated leader from (current) leader's message
ByteBuffer buffer = ByteBuffer.wrap(qp.getData());
long suggestedLeaderId = buffer.getLong();
boolean majorChange =
self.processReconfig(qv, suggestedLeaderId, qp.getZxid(), true);
// commit (writes the new config to ZK tree (/zookeeper/config)
fzk.commit(qp.getZxid());
if (majorChange) {
throw new Exception("changes proposed in reconfig");
}
break;
case Leader.UPTODATE:
LOG.error("Received an UPTODATE message after Follower started");
break;
case Leader.REVALIDATE:
revalidate(qp);
break;
case Leader.SYNC:
//同步请求
fzk.sync();
break;
default:
LOG.warn("Unknown packet type: {}", LearnerHandler.packetToString(qp));
break;
}
跟随者处理消息包,如果为提议消息,则log请求,提交消息,则委托给commit处理器处理,如果为同步请求则从同步请求队列拉取消息,并委托给commit处理器处理。
再来看领导者状态
###
case LEADING:
//Leader
LOG.info("LEADING");
try {
//org.apache.zookeeper.server.quorum.Learner
//org.apache.zookeeper.server.quorum.LearnerZooKeeperServer
setLeader(makeLeader(logFactory));
//lead
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
updateServerState();
}
break;
}
//
/**
* This class has the control logic for the Leader.
*/
public class Leader {
...
/**
* This method is main function that is called to lead
*
* @throws IOException
* @throws InterruptedException
*/
void lead() throws IOException, InterruptedException {
self.end_fle = Time.currentElapsedTime();
long electionTimeTaken = self.end_fle - self.start_fle;
self.setElectionTimeTaken(electionTimeTaken);
LOG.info("LEADING - LEADER ELECTION TOOK - {} {}", electionTimeTaken,
QuorumPeer.FLE_TIME_UNIT);
self.start_fle = 0;
self.end_fle = 0;
zk.registerJMX(new LeaderBean(this, zk), self.jmxLocalPeerBean);
try {
self.tick.set(0);
//加载数据
zk.loadData();
leaderStateSummary = new StateSummary(self.getCurrentEpoch(), zk.getLastProcessedZxid());
// Start thread that waits for connection requests from
// new followers.
//启动learner 监听器,接收follower的请求
cnxAcceptor = new LearnerCnxAcceptor();
cnxAcceptor.start();
//获取当前提议时间点
long epoch = getEpochToPropose(self.getId(), self.getAcceptedEpoch());
zk.setZxid(ZxidUtils.makeZxid(epoch, 0));
synchronized(this){
lastProposed = zk.getZxid();
}
//创建新leader数据包
newLeaderProposal.packet = new QuorumPacket(NEWLEADER, zk.getZxid(),
null, null);
if ((newLeaderProposal.packet.getZxid() & 0xffffffffL) != 0) {
LOG.info("NEWLEADER proposal has Zxid of "
+ Long.toHexString(newLeaderProposal.packet.getZxid()));
}
QuorumVerifier lastSeenQV = self.getLastSeenQuorumVerifier();
QuorumVerifier curQV = self.getQuorumVerifier();
if (curQV.getVersion() == 0 && curQV.getVersion() == lastSeenQV.getVersion()) {
// This was added in ZOOKEEPER-1783. The initial config has version 0 (not explicitly
// specified by the user; the lack of version in a config file is interpreted as version=0).
// As soon as a config is established we would like to increase its version so that it
// takes presedence over other initial configs that were not established (such as a config
// of a server trying to join the ensemble, which may be a partial view of the system, not the full config).
// We chose to set the new version to the one of the NEWLEADER message. However, before we can do that
// there must be agreement on the new version, so we can only change the version when sending/receiving UPTODATE,
// not when sending/receiving NEWLEADER. In other words, we can't change curQV here since its the committed quorum verifier,
// and there's still no agreement on the new version that we'd like to use. Instead, we use
// lastSeenQuorumVerifier which is being sent with NEWLEADER message
// so its a good way to let followers know about the new version. (The original reason for sending
// lastSeenQuorumVerifier with NEWLEADER is so that the leader completes any potentially uncommitted reconfigs
// that it finds before starting to propose operations. Here we're reusing the same code path for
// reaching consensus on the new version number.)
// It is important that this is done before the leader executes waitForEpochAck,
// so before LearnerHandlers return from their waitForEpochAck
// hence before they construct the NEWLEADER message containing
// the last-seen-quorumverifier of the leader, which we change below
try {
QuorumVerifier newQV = self.configFromString(curQV.toString());
newQV.setVersion(zk.getZxid());
self.setLastSeenQuorumVerifier(newQV, true);
} catch (Exception e) {
throw new IOException(e);
}
}
newLeaderProposal.addQuorumVerifier(self.getQuorumVerifier());
if (self.getLastSeenQuorumVerifier().getVersion() > self.getQuorumVerifier().getVersion()){
newLeaderProposal.addQuorumVerifier(self.getLastSeenQuorumVerifier());
}
// We have to get at least a majority of servers in sync with
// us. We do this by waiting for the NEWLEADER packet to get
//等所有Quorum, peer 全部投票完毕
waitForEpochAck(self.getId(), leaderStateSummary);
self.setCurrentEpoch(epoch);
try {
//处理新sid的NEWLEADER, 直到leader接收到充足的回复
waitForNewLeaderAck(self.getId(), zk.getZxid(), LearnerType.PARTICIPANT);
} catch (InterruptedException e) {
shutdown("Waiting for a quorum of followers, only synced with sids: [ "
+ newLeaderProposal.ackSetsToString() + " ]");
HashSet<Long> followerSet = new HashSet<Long>();
for(LearnerHandler f : getLearners()) {
if (self.getQuorumVerifier().getVotingMembers().containsKey(f.getSid())){
followerSet.add(f.getSid());
}
}
boolean initTicksShouldBeIncreased = true;
for (Proposal.QuorumVerifierAcksetPair qvAckset:newLeaderProposal.qvAcksetPairs) {
if (!qvAckset.getQuorumVerifier().containsQuorum(followerSet)) {
initTicksShouldBeIncreased = false;
break;
}
}
if (initTicksShouldBeIncreased) {
LOG.warn("Enough followers present. "+
"Perhaps the initTicks need to be increased.");
}
return;
}
startZkServer();
/**
* WARNING: do not use this for anything other than QA testing
* on a real cluster. Specifically to enable verification that quorum
* can handle the lower 32bit roll-over issue identified in
* ZOOKEEPER-1277. Without this option it would take a very long
* time (on order of a month say) to see the 4 billion writes
* necessary to cause the roll-over to occur.
*
* This field allows you to override the zxid of the server. Typically
* you'll want to set it to something like 0xfffffff0 and then
* start the quorum, run some operations and see the re-election.
*/
String initialZxid = System.getProperty("zookeeper.testingonly.initialZxid");
if (initialZxid != null) {
long zxid = Long.parseLong(initialZxid);
zk.setZxid((zk.getZxid() & 0xffffffff00000000L) | zxid);
}
if (!System.getProperty("zookeeper.leaderServes", "yes").equals("no")) {
self.setZooKeeperServer(zk);
}
self.adminServer.setZooKeeperServer(zk);
// Everything is a go, simply start counting the ticks
// WARNING: I couldn't find any wait statement on a synchronized
// block that would be notified by this notifyAll() call, so
// I commented it out
//synchronized (this) {
// notifyAll();
//}
// We ping twice a tick, so we only update the tick every other
// iteration
boolean tickSkip = true;
// If not null then shutdown this leader
String shutdownMessage = null;
while (true) {
synchronized (this) {
long start = Time.currentElapsedTime();
long cur = start;
long end = start + self.tickTime / 2;
while (cur < end) {
wait(end - cur);
cur = Time.currentElapsedTime();
}
if (!tickSkip) {
self.tick.incrementAndGet();
}
//开启同步learner追踪器,以确保拥有同一个的quorum视图
// We use an instance of SyncedLearnerTracker to
// track synced learners to make sure we still have a
// quorum of current (and potentially next pending) view.
SyncedLearnerTracker syncedAckSet = new SyncedLearnerTracker();
syncedAckSet.addQuorumVerifier(self.getQuorumVerifier());
if (self.getLastSeenQuorumVerifier() != null
&& self.getLastSeenQuorumVerifier().getVersion() > self
.getQuorumVerifier().getVersion()) {
syncedAckSet.addQuorumVerifier(self
.getLastSeenQuorumVerifier());
}
syncedAckSet.addAck(self.getId());
for (LearnerHandler f : getLearners()) {
if (f.synced()) {
syncedAckSet.addAck(f.getSid());
}
}
// check leader running status
if (!this.isRunning()) {
// set shutdown flag
shutdownMessage = "Unexpected internal error";
break;
}
if (!tickSkip && !syncedAckSet.hasAllQuorums()) {
// Lost quorum of last committed and/or last proposed
// config, set shutdown flag
shutdownMessage = "Not sufficient followers synced, only synced with sids: [ "
+ syncedAckSet.ackSetsToString() + " ]";
break;
}
tickSkip = !tickSkip;
}
for (LearnerHandler f : getLearners()) {
f.ping();
}
}
if (shutdownMessage != null) {
shutdown(shutdownMessage);
// leader goes in looking state
}
} finally {
zk.unregisterJMX(this);
}
}
}
领导者首先加载数据到内存数据库,创建新leader数据包,然后等待所有Quorum, peer 全部投票完毕, 启动server(LeaderZooKeeperServer)。
在leader,follower以及观察者选举操作完后,要更新节点的状态,我们来看一下状态是怎么更新的。
/**
* 更新server状态
*/
private synchronized void updateServerState(){
if (!reconfigFlag) {
setPeerState(ServerState.LOOKING);
LOG.warn("PeerState set to LOOKING");
return;
}
if (getId() == getCurrentVote().getId()) {
//如果投票的leader id为当前server id, 则为leader
setPeerState(ServerState.LEADING);
LOG.debug("PeerState set to LEADING");
} else if (getLearnerType() == LearnerType.PARTICIPANT) {
//如果为参与者,则为FOLLOWING
setPeerState(ServerState.FOLLOWING);
LOG.debug("PeerState set to FOLLOWING");
} else if (getLearnerType() == LearnerType.OBSERVER) {
//观察者
setPeerState(ServerState.OBSERVING);
LOG.debug("PeerState set to OBSERVER");
} else { // currently shouldn't happen since there are only 2 learner types
setPeerState(ServerState.LOOKING);
LOG.debug("Shouldn't be here");
}
reconfigFlag = false;
}
如果集群没有配置,则为LOOING状态,如果节点投注的serverId为当前节点,则为Leader,如果学习的类型为参与者,则为节点状态为跟踪者,如果学习类型为观察状态,则为观察者。
总结
跟随者,跟随领导者首先连接leader,注册follower状态,在leader连接的过程中,如果发现消息队列中有LEADERINFO请求,则响应leader然后同步leader,这部分逻辑和观察者一致,主要有同步leader日志快照,如果为TUNC命令,则截取事务日志。
跟随者处理消息包,如果为提议消息,则log请求,提交消息,则委托给commit处理器处理,如果为同步请求则从同步请求队列拉取消息,并委托给commit处理器处理。
领导者首先加载数据到内存数据库,创建新leader数据包,然后等待所有Quorum, peer 全部投票完毕, 启动server(LeaderZooKeeperServer)。
节点状态的确定逻辑为集群没有配置,则为LOOING状态,如果节点投注的serverId为当前节点,则为Leader,如果学习的类型为参与者,则为节点状态为跟踪者,如果学习类型为观察状态,则为观察者。