Zookeeper框架设计及源码解读八(数据存储)
write by valuewithTime, 2021-01-11 21:02引言
针对跟随者,SendAckRequestProcessor处理器,针对非同步操作,回复ACK。 SyncRequestProcessor处理器从请求队列拉取请求,针对刷新队列不为空的情况,如果请求队列为空,则提交请求日志,并刷新到磁盘,否则根据日志计数器和快照计数器计算是否需要拍摄快照。 FollowerRequestProcessor处理器,从请求队列拉取请求,如果请求为同步请求,则添加请求到同步队列, 并转发请求给leader,如果为CRUD相关的操作,直接转发请求给leader。
针对观察者,观察者请求处理器,从请求队列拉取请求,如果请求为同步请求,则添加请求到同步队列, 并转发请求给leader,如果为CRUD相关的操作,直接转发请求给leader。
今天我们来看一下数据存储这一块。
目录
概要框架设计
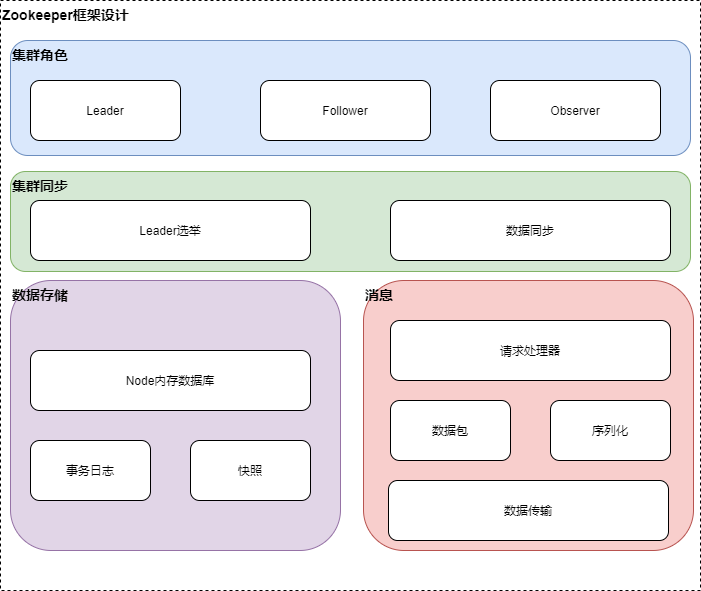
Zookeeper整体架构主要分为数据的存储,消息,leader选举和数据同步这几个模块。leader选举主要是在集群处于混沌的状态下,从集群peer的提议中选择集群的leader,其他为follower或observer,维护集群peer的统一视图,保证整个集群的数据一致性,如果在leader选举成功后,存在follower日志落后的情况,则将事务日志同步给follower。针对消息模块,peer之间的通信包需要序列化和反序列才能发送和处理,具体的消息处理由集群相应角色的消息处理器链来处理。针对客户单的节点的创建,数据修改等操作,将会先写到内存数据库,如果有提交请求,则将数据写到事务日志,同时Zookeeper会定时将内存数据库写到快照日志,以防止没有提交的日志,在宕机的情况下丢失。数据同步模块将leader的事务日志同步给Follower,保证整个集群数据的一致性。
源码分析
源码分析仓库,见 zookeeper github
启动Zookeeper
Zookeeper框架设计及源码解读一(Zookeeper启动)
Leader选举
Zookeeper框架设计及源码解读二(快速选举策略及选举消息的发送与接收)
LOOKING提议投票阶段
Zookeeper框架设计及源码解读三(leader选举LOOKING阶段)
OBSERVING观察者同步leader
Zookeeper框架设计及源码解读四(观察者观察leader)
FOLLOWING跟随者状态
LEADING领导者状态
Zookeeper框架设计及源码解读五(跟随者状态、领导者状态)
消息处理
Leader消息处理
Zookeeper框架设计及源码解读六(Leader消息处理)
Follower消息处理
Observer消息处理
Zookeeper框架设计及源码解读七(跟随者观察者消息处理器)
数据存储
//ZKDatabase
/**
* This class maintains the in memory database of zookeeper
* server states that includes the sessions, datatree and the
* committed logs. It is booted up after reading the logs
* and snapshots from the disk.
* zkserver状态内存数据库,包括所有的会话,数据树,提交日志。在从磁盘读取日志和快照后,启动
*/
public class ZKDatabase {
private static final Logger LOG = LoggerFactory.getLogger(ZKDatabase.class);
/**
* make sure on a clear you take care of
* all these members.
*/
protected DataTree dataTree;
/**
*
*/
protected ConcurrentHashMap<Long, Integer> sessionsWithTimeouts;
/**
*
*/
protected FileTxnSnapLog snapLog;
/**
*
*/
protected long minCommittedLog, maxCommittedLog;
/**
* Default value is to use snapshot if txnlog size exceeds 1/3 the size of snapshot
*/
public static final String SNAPSHOT_SIZE_FACTOR = "zookeeper.snapshotSizeFactor";
public static final double DEFAULT_SNAPSHOT_SIZE_FACTOR = 0.33;
private double snapshotSizeFactor;
public static final int commitLogCount = 500;
protected static int commitLogBuffer = 700;
/**
* 提议请求
*/
protected LinkedList<Proposal> committedLog = new LinkedList<Proposal>();
protected ReentrantReadWriteLock logLock = new ReentrantReadWriteLock();
volatile private boolean initialized = false;
/**
* the filetxnsnaplog that this zk database
* maps to. There is a one to one relationship
* between a filetxnsnaplog and zkdatabase.
* @param snapLog the FileTxnSnapLog mapping this zkdatabase
*/
public ZKDatabase(FileTxnSnapLog snapLog) {
dataTree = new DataTree();
sessionsWithTimeouts = new ConcurrentHashMap<Long, Integer>();
this.snapLog = snapLog;
try {
snapshotSizeFactor = Double.parseDouble(
System.getProperty(SNAPSHOT_SIZE_FACTOR,
Double.toString(DEFAULT_SNAPSHOT_SIZE_FACTOR)));
if (snapshotSizeFactor > 1) {
snapshotSizeFactor = DEFAULT_SNAPSHOT_SIZE_FACTOR;
LOG.warn("The configured {} is invalid, going to use " +
"the default {}", SNAPSHOT_SIZE_FACTOR,
DEFAULT_SNAPSHOT_SIZE_FACTOR);
}
} catch (NumberFormatException e) {
LOG.error("Error parsing {}, using default value {}",
SNAPSHOT_SIZE_FACTOR, DEFAULT_SNAPSHOT_SIZE_FACTOR);
snapshotSizeFactor = DEFAULT_SNAPSHOT_SIZE_FACTOR;
}
LOG.info("{} = {}", SNAPSHOT_SIZE_FACTOR, snapshotSizeFactor);
}
...
}
从上面可以看出,ZK数据库ZKDatabase主要有数据树DataTree和文件快照日志FileTxnSnapLog.
//ZKDatabase
/**
* append to the underlying transaction log
* 添加底层事物日志
* @param si the request to append
* @return true if the append was succesfull and false if not
*/
public boolean append(Request si) throws IOException {
return this.snapLog.append(si);
}
/**
* roll the underlying log
*/
public void rollLog() throws IOException {
this.snapLog.rollLog();
}
/**
* commit to the underlying transaction log
* @throws IOException
*/
public void commit() throws IOException {
this.snapLog.commit();
}
/**
* Truncate the ZKDatabase to the specified zxid
* 截断日志
* @param zxid the zxid to truncate zk database to
* @return true if the truncate is successful and false if not
* @throws IOException
*/
public boolean truncateLog(long zxid) throws IOException {
clear();
// truncate the log
boolean truncated = snapLog.truncateLog(zxid);
if (!truncated) {
return false;
}
loadDataBase();
return true;
}
从上面可以看出,日志添加,提交,回滚,截断,委托给文件快照日志FileTxnSnapLog。
再来看一下请求处理 //ZKDatabase
/**
* the process txn on the data
* @param hdr the txnheader for the txn
* @param txn the transaction that needs to be processed
* @return the result of processing the transaction on this
* datatree/zkdatabase
*/
public ProcessTxnResult processTxn(TxnHeader hdr, Record txn) {
return dataTree.processTxn(hdr, txn);
}
/**
* stat the path
* @param path the path for which stat is to be done
* @param serverCnxn the servercnxn attached to this request
* @return the stat of this node
* @throws KeeperException.NoNodeException
*/
public Stat statNode(String path, ServerCnxn serverCnxn) throws KeeperException.NoNodeException {
return dataTree.statNode(path, serverCnxn);
}
/**
* get the datanode for this path
* @param path the path to lookup
* @return the datanode for getting the path
*/
public DataNode getNode(String path) {
return dataTree.getNode(path);
}
从上面可以看出,请求处理,获取节点数据,委托给有数据树DataTree。
来看一下具体事务日志log和请求的处理
FileTxnSnapLog
//FileTxnSnapLog
/**
* This is a helper class
* above the implementations
* of txnlog and snapshot
* classes
* 交易快照日志
*/
public class FileTxnSnapLog {
//the directory containing the
//the transaction logs
private final File dataDir;
//the directory containing the
//the snapshot directory
private final File snapDir;
private TxnLog txnLog;
private SnapShot snapLog;
private final boolean autoCreateDB;
public final static int VERSION = 2;
public final static String version = "version-";
private static final Logger LOG = LoggerFactory.getLogger(FileTxnSnapLog.class);
public static final String ZOOKEEPER_DATADIR_AUTOCREATE =
"zookeeper.datadir.autocreate";
public static final String ZOOKEEPER_DATADIR_AUTOCREATE_DEFAULT = "true";
static final String ZOOKEEPER_DB_AUTOCREATE = "zookeeper.db.autocreate";
private static final String ZOOKEEPER_DB_AUTOCREATE_DEFAULT = "true";
/**
* This listener helps
* the external apis calling
* restore to gather information
* while the data is being
* restored.
*/
public interface PlayBackListener {
void onTxnLoaded(TxnHeader hdr, Record rec);
}
/**
* the constructor which takes the datadir and
* snapdir.
* @param dataDir the transaction directory
* @param snapDir the snapshot directory
*/
public FileTxnSnapLog(File dataDir, File snapDir) throws IOException {
LOG.debug("Opening datadir:{} snapDir:{}", dataDir, snapDir);
this.dataDir = new File(dataDir, version + VERSION);
this.snapDir = new File(snapDir, version + VERSION);
// by default create snap/log dirs, but otherwise complain instead
// See ZOOKEEPER-1161 for more details
boolean enableAutocreate = Boolean.valueOf(
System.getProperty(ZOOKEEPER_DATADIR_AUTOCREATE,
ZOOKEEPER_DATADIR_AUTOCREATE_DEFAULT));
if (!this.dataDir.exists()) {
if (!enableAutocreate) {
throw new DatadirException("Missing data directory "
+ this.dataDir
+ ", automatic data directory creation is disabled ("
+ ZOOKEEPER_DATADIR_AUTOCREATE
+ " is false). Please create this directory manually.");
}
if (!this.dataDir.mkdirs()) {
throw new DatadirException("Unable to create data directory "
+ this.dataDir);
}
}
if (!this.dataDir.canWrite()) {
throw new DatadirException("Cannot write to data directory " + this.dataDir);
}
if (!this.snapDir.exists()) {
// by default create this directory, but otherwise complain instead
// See ZOOKEEPER-1161 for more details
if (!enableAutocreate) {
throw new DatadirException("Missing snap directory "
+ this.snapDir
+ ", automatic data directory creation is disabled ("
+ ZOOKEEPER_DATADIR_AUTOCREATE
+ " is false). Please create this directory manually.");
}
if (!this.snapDir.mkdirs()) {
throw new DatadirException("Unable to create snap directory "
+ this.snapDir);
}
}
if (!this.snapDir.canWrite()) {
throw new DatadirException("Cannot write to snap directory " + this.snapDir);
}
// check content of transaction log and snapshot dirs if they are two different directories
// See ZOOKEEPER-2967 for more details
if(!this.dataDir.getPath().equals(this.snapDir.getPath())){
checkLogDir();
checkSnapDir();
}
txnLog = new FileTxnLog(this.dataDir);
snapLog = new FileSnap(this.snapDir);
autoCreateDB = Boolean.parseBoolean(System.getProperty(ZOOKEEPER_DB_AUTOCREATE,
ZOOKEEPER_DB_AUTOCREATE_DEFAULT));
}
...
}
从上面可以看出交易快照日志有两部分组成一个是已提交的事务日志文件目录dataDir,快照日志文件目录snapDir组成。 事务日志txnLog对应的为FileTxnLog, 快照日志snapLog为FileSnap。
来看一下提交日志
//
/**
* commit the transaction of logs
* @throws IOException
*/
public void commit() throws IOException {
txnLog.commit();
}
//FileTxnLog
public class FileTxnLog implements TxnLog {
private static final Logger LOG;
public final static int TXNLOG_MAGIC =
ByteBuffer.wrap("ZKLG".getBytes()).getInt();
public final static int VERSION = 2;
public static final String LOG_FILE_PREFIX = "log";
/** Maximum time we allow for elapsed fsync before WARNing */
private final static long fsyncWarningThresholdMS;
static {
LOG = LoggerFactory.getLogger(FileTxnLog.class);
/** Local variable to read fsync.warningthresholdms into */
Long fsyncWarningThreshold;
if ((fsyncWarningThreshold = Long.getLong("zookeeper.fsync.warningthresholdms")) == null)
fsyncWarningThreshold = Long.getLong("fsync.warningthresholdms", 1000);
fsyncWarningThresholdMS = fsyncWarningThreshold;
}
long lastZxidSeen;
volatile BufferedOutputStream logStream = null;
volatile OutputArchive oa;
volatile FileOutputStream fos = null;
File logDir;
private final boolean forceSync = !System.getProperty("zookeeper.forceSync", "yes").equals("no");
long dbId;
private LinkedList<FileOutputStream> streamsToFlush =
new LinkedList<FileOutputStream>();
File logFileWrite = null;
private FilePadding filePadding = new FilePadding();
private volatile long syncElapsedMS = -1L;
/**
* constructor for FileTxnLog. Take the directory
* where the txnlogs are stored
* @param logDir the directory where the txnlogs are stored
*/
public FileTxnLog(File logDir) {
this.logDir = logDir;
}
...
//FileTxnLog
/**
* commit the logs. make sure that everything hits the
* disk
*/
public synchronized void commit() throws IOException {
if (logStream != null) {
logStream.flush();
}
for (FileOutputStream log : streamsToFlush) {
log.flush();
if (forceSync) {
long startSyncNS = System.nanoTime();
FileChannel channel = log.getChannel();
channel.force(false);
syncElapsedMS = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startSyncNS);
if (syncElapsedMS > fsyncWarningThresholdMS) {
LOG.warn("fsync-ing the write ahead log in "
+ Thread.currentThread().getName()
+ " took " + syncElapsedMS
+ "ms which will adversely effect operation latency. "
+ "File size is " + channel.size() + " bytes. "
+ "See the ZooKeeper troubleshooting guide");
}
}
}
while (streamsToFlush.size() > 1) {
streamsToFlush.removeFirst().close();
}
}
从上面可以看出,提交事务实际,实际为将文件输出流,刷新磁盘(事务日志文件目录)。
再来看,回滚日志
/**
* rollover the current log file to a new one.
*
* @throws IOException
*/
public synchronized void rollLog() throws IOException {
if (logStream != null) {
this.logStream.flush();
this.logStream = null;
oa = null;
}
}
从上面看出,回滚事务日志,实际为重置日志流logStream为BufferedOutputStream为null。
再来看一下截断日志
/**
* truncate the current transaction logs
* @param zxid the zxid to truncate the logs to
* @return true if successful false if not
*/
public boolean truncate(long zxid) throws IOException {
FileTxnIterator itr = null;
try {
itr = new FileTxnIterator(this.logDir, zxid);
PositionInputStream input = itr.inputStream;
if(input == null) {
throw new IOException("No log files found to truncate! This could " +
"happen if you still have snapshots from an old setup or " +
"log files were deleted accidentally or dataLogDir was changed in zoo.cfg.");
}
long pos = input.getPosition();
// now, truncate at the current position
RandomAccessFile raf=new RandomAccessFile(itr.logFile,"rw");
raf.setLength(pos);
raf.close();
while(itr.goToNextLog()) {
if (!itr.logFile.delete()) {
LOG.warn("Unable to truncate {}", itr.logFile);
}
}
} finally {
close(itr);
}
return true;
}
/**
* create an iterator over a transaction database directory
* @param logDir the transaction database directory
* @param zxid the zxid to start reading from
* @throws IOException
*/
public FileTxnIterator(File logDir, long zxid) throws IOException {
this(logDir, zxid, true);
}
/**
* initialize to the zxid specified
* this is inclusive of the zxid
* @throws IOException
*/
void init() throws IOException {
storedFiles = new ArrayList<File>();
List<File> files = Util.sortDataDir(FileTxnLog.getLogFiles(logDir.listFiles(), 0), LOG_FILE_PREFIX, false);
for (File f: files) {
if (Util.getZxidFromName(f.getName(), LOG_FILE_PREFIX) >= zxid) {
storedFiles.add(f);
}
// add the last logfile that is less than the zxid
else if (Util.getZxidFromName(f.getName(), LOG_FILE_PREFIX) < zxid) {
storedFiles.add(f);
break;
}
}
goToNextLog();
next();
}
从上面可以看出,截断日志,实际为根据事务zxid, 删除大于zxid的事务日志文件。
再来看一下拍摄快照
//ZookeeperServer
/**
* 拍摄zk数据树快照
* @param syncSnap
*/
public void takeSnapshot(boolean syncSnap){
try {
txnLogFactory.save(zkDb.getDataTree(), zkDb.getSessionWithTimeOuts(), syncSnap);
} catch (IOException e) {
LOG.error("Severe unrecoverable error, exiting", e);
// This is a severe error that we cannot recover from,
// so we need to exit
System.exit(10);
}
}
//FileTxnSnapLog
/**
* save the datatree and the sessions into a snapshot
* 保存zk数据树快照
* @param dataTree the datatree to be serialized onto disk
* @param sessionsWithTimeouts the session timeouts to be
* serialized onto disk
* @param syncSnap sync the snapshot immediately after write
* @throws IOException
*/
public void save(DataTree dataTree,
ConcurrentHashMap<Long, Integer> sessionsWithTimeouts,
boolean syncSnap)
throws IOException {
long lastZxid = dataTree.lastProcessedZxid;
//快照文件
File snapshotFile = new File(snapDir, Util.makeSnapshotName(lastZxid));
LOG.info("Snapshotting: 0x{} to {}", Long.toHexString(lastZxid),
snapshotFile);
snapLog.serialize(dataTree, sessionsWithTimeouts, snapshotFile, syncSnap);
}
//FileSnap
/**
* serialize the datatree and session into the file snapshot
* @param dt the datatree to be serialized
* @param sessions the sessions to be serialized
* @param snapShot the file to store snapshot into
* @param fsync sync the file immediately after write
*/
public synchronized void serialize(DataTree dt, Map<Long, Integer> sessions, File snapShot, boolean fsync)
throws IOException {
if (!close) {
try (CheckedOutputStream crcOut =
new CheckedOutputStream(new BufferedOutputStream(fsync ? new AtomicFileOutputStream(snapShot) :
new FileOutputStream(snapShot)),
new Adler32())) {
//CheckedOutputStream cout = new CheckedOutputStream()
OutputArchive oa = BinaryOutputArchive.getArchive(crcOut);
FileHeader header = new FileHeader(SNAP_MAGIC, VERSION, dbId);
serialize(dt, sessions, oa, header);
long val = crcOut.getChecksum().getValue();
oa.writeLong(val, "val");
oa.writeString("/", "path");
crcOut.flush();
}
}
}
从上面可以看出,拍摄快照,实际为将DataTree,序列化到快照日志文件。
小节一下
提交事务实际,实际为将文件输出流,刷新磁盘(事务日志文件目录)。 回滚事务日志,实际为重置日志流logStream为BufferedOutputStream为null。 截断日志,实际为根据事务zxid, 删除大于zxid的事务日志文件。 拍摄快照,实际为将DataTree,序列化到快照日志文件。
再来看一下数据树
DataTree
//DataTree
public class DataTree {
private static final Logger LOG = LoggerFactory.getLogger(DataTree.class);
/**
* This hashtable provides a fast lookup to the datanodes. The tree is the
* source of truth and is where all the locking occurs
* 节点快速查找hashtable
*/
private final ConcurrentHashMap<String, DataNode> nodes =
new ConcurrentHashMap<String, DataNode>();
/**
* 数据观察器
*/
private final WatchManager dataWatches = new WatchManager();
/**
* 子节点观察器
*/
private final WatchManager childWatches = new WatchManager();
/** the root of zookeeper tree */
private static final String rootZookeeper = "/";
/** the zookeeper nodes that acts as the management and status node **/
private static final String procZookeeper = Quotas.procZookeeper;
/** this will be the string thats stored as a child of root */
private static final String procChildZookeeper = procZookeeper.substring(1);
/**
* the zookeeper quota node that acts as the quota management node for
* zookeeper
*/
private static final String quotaZookeeper = Quotas.quotaZookeeper;
/** this will be the string thats stored as a child of /zookeeper */
private static final String quotaChildZookeeper = quotaZookeeper
.substring(procZookeeper.length() + 1);
/**
* the zookeeper config node that acts as the config management node for
* zookeeper
*/
private static final String configZookeeper = ZooDefs.CONFIG_NODE;
/** this will be the string thats stored as a child of /zookeeper */
private static final String configChildZookeeper = configZookeeper
.substring(procZookeeper.length() + 1);
/**
* the path trie that keeps track fo the quota nodes in this datatree
*/
private final PathTrie pTrie = new PathTrie();
/**
* This hashtable lists the paths of the ephemeral nodes of a session.
* 会话历史节点
*/
private final Map<Long, HashSet<String>> ephemerals =
new ConcurrentHashMap<Long, HashSet<String>>();
/**
* This set contains the paths of all container nodes
* 容器节点
*/
private final Set<String> containers =
Collections.newSetFromMap(new ConcurrentHashMap<String, Boolean>());
/**
* This set contains the paths of all ttl nodes
* 所有ttl节点
*/
private final Set<String> ttls =
Collections.newSetFromMap(new ConcurrentHashMap<String, Boolean>());
private final ReferenceCountedACLCache aclCache = new ReferenceCountedACLCache();
...
/**
* This is a pointer to the root of the DataTree. It is the source of truth,
* but we usually use the nodes hashmap to find nodes in the tree.
*/
private DataNode root = new DataNode(new byte[0], -1L, new StatPersisted());
/**
* create a /zookeeper filesystem that is the proc filesystem of zookeeper
*/
private final DataNode procDataNode = new DataNode(new byte[0], -1L, new StatPersisted());
/**
* create a /zookeeper/quota node for maintaining quota properties for
* zookeeper
*/
private final DataNode quotaDataNode = new DataNode(new byte[0], -1L, new StatPersisted());
public DataTree() {
/* Rather than fight it, let root have an alias */
nodes.put("", root);
nodes.put(rootZookeeper, root);
/** add the proc node and quota node */
root.addChild(procChildZookeeper);
nodes.put(procZookeeper, procDataNode);
procDataNode.addChild(quotaChildZookeeper);
nodes.put(quotaZookeeper, quotaDataNode);
addConfigNode();
}
}
从上面可以看出, DataNode主要是通过节点HashMap来维护节点信息(ConcurrentHashMap<String, DataNode>())。
再看一下数据node
//DataNode
public class DataNode implements Record {
/** the data for this datanode */
byte data[];
/**
* the acl map long for this datanode. the datatree has the map
*/
Long acl;
/**
* the stat for this node that is persisted to disk.
* 对象持久化状态
*/
public StatPersisted stat;
/**
* the list of children for this node. note that the list of children string
* does not contain the parent path -- just the last part of the path. This
* should be synchronized on except deserializing (for speed up issues).
* 子节点路径
*/
private Set<String> children = null;
private static final Set<String> EMPTY_SET = Collections.emptySet();
/**
* @param archive
* @param tag
* @throws IOException
*/
synchronized public void deserialize(InputArchive archive, String tag)
throws IOException {
archive.startRecord("node");
data = archive.readBuffer("data");
acl = archive.readLong("acl");
stat = new StatPersisted();
stat.deserialize(archive, "statpersisted");
archive.endRecord("node");
}
/**
* @param archive
* @param tag
* @throws IOException
*/
synchronized public void serialize(OutputArchive archive, String tag)
throws IOException {
archive.startRecord(this, "node");
archive.writeBuffer(data, "data");
archive.writeLong(acl, "acl");
stat.serialize(archive, "statpersisted");
archive.endRecord(this, "node");
}
从上面可以看出,数据DataNode有一个字节数组(byte data[])存储数据,Set
再看一下如何处理请求;
先看一下,创建节点 //
/**
* 处理事务
* @param header
* @param txn
* @return
*/
public ProcessTxnResult processTxn(TxnHeader header, Record txn)
{
ProcessTxnResult rc = new ProcessTxnResult();
try {
rc.clientId = header.getClientId();
rc.cxid = header.getCxid();
rc.zxid = header.getZxid();
rc.type = header.getType();
rc.err = 0;
rc.multiResult = null;
switch (header.getType()) {
//创建节点
case OpCode.create:
CreateTxn createTxn = (CreateTxn) txn;
rc.path = createTxn.getPath();
createNode(
createTxn.getPath(),
createTxn.getData(),
createTxn.getAcl(),
createTxn.getEphemeral() ? header.getClientId() : 0,
createTxn.getParentCVersion(),
header.getZxid(), header.getTime(), null);
break;
...
}
}
}
/**
* Add a new node to the DataTree.
* 添加新的节点,到数据树
* @param path
* Path for the new node.
* @param data
* Data to store in the node.
* @param acl
* Node acls
* @param ephemeralOwner
* the session id that owns this node. -1 indicates this is not
* an ephemeral node.
* @param zxid
* Transaction ID
* @param time
* @param outputStat
* A Stat object to store Stat output results into.
* @throws NodeExistsException
* @throws NoNodeException
* @throws KeeperException
*/
public void createNode(final String path, byte data[], List<ACL> acl,
long ephemeralOwner, int parentCVersion, long zxid, long time, Stat outputStat)
throws KeeperException.NoNodeException,
KeeperException.NodeExistsException {
int lastSlash = path.lastIndexOf('/');
String parentName = path.substring(0, lastSlash);
String childName = path.substring(lastSlash + 1);
StatPersisted stat = new StatPersisted();
stat.setCtime(time);
stat.setMtime(time);
stat.setCzxid(zxid);
stat.setMzxid(zxid);
stat.setPzxid(zxid);
stat.setVersion(0);
stat.setAversion(0);
stat.setEphemeralOwner(ephemeralOwner);
DataNode parent = nodes.get(parentName);
if (parent == null) {
throw new KeeperException.NoNodeException();
}
synchronized (parent) {
Set<String> children = parent.getChildren();
if (children.contains(childName)) {
throw new KeeperException.NodeExistsException();
}
if (parentCVersion == -1) {
parentCVersion = parent.stat.getCversion();
parentCVersion++;
}
parent.stat.setCversion(parentCVersion);
parent.stat.setPzxid(zxid);
// set ack and put to datatree
Long longval = aclCache.convertAcls(acl);
DataNode child = new DataNode(data, longval, stat);
parent.addChild(childName);
nodes.put(path, child);
EphemeralType ephemeralType = EphemeralType.get(ephemeralOwner);
if (ephemeralType == EphemeralType.CONTAINER) {
containers.add(path);
} else if (ephemeralType == EphemeralType.TTL) {
ttls.add(path);
} else if (ephemeralOwner != 0) {
HashSet<String> list = ephemerals.get(ephemeralOwner);
if (list == null) {
list = new HashSet<String>();
ephemerals.put(ephemeralOwner, list);
}
synchronized (list) {
list.add(path);
}
}
if (outputStat != null) {
child.copyStat(outputStat);
}
}
// now check if its one of the zookeeper node child
if (parentName.startsWith(quotaZookeeper)) {
// now check if its the limit node
if (Quotas.limitNode.equals(childName)) {
// this is the limit node
// get the parent and add it to the trie
pTrie.addPath(parentName.substring(quotaZookeeper.length()));
}
if (Quotas.statNode.equals(childName)) {
updateQuotaForPath(parentName
.substring(quotaZookeeper.length()));
}
}
// also check to update the quotas for this node
String lastPrefix = getMaxPrefixWithQuota(path);
if(lastPrefix != null) {
// ok we have some match and need to update
updateCount(lastPrefix, 1);
updateBytes(lastPrefix, data == null ? 0 : data.length);
}
dataWatches.triggerWatch(path, Event.EventType.NodeCreated);
childWatches.triggerWatch(parentName.equals("") ? "/" : parentName,
Event.EventType.NodeChildrenChanged);
}
从上面可以看出,创建节点实际为添加一个Datanode到数据树DataTree。
来看获取节点信息
/**
* 获取节点数据
* @param path
* @param stat
* @param watcher
* @return
* @throws KeeperException.NoNodeException
*/
public byte[] getData(String path, Stat stat, Watcher watcher)
throws KeeperException.NoNodeException {
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
n.copyStat(stat);
if (watcher != null) {
dataWatches.addWatch(path, watcher);
}
return n.data;
}
}
从上面可以看出,获取节点数据,实际为从节点HashMap中获取DataNode信息。
总结
ZK数据库ZKDatabase主要有数据树DataTree和文件快照日志FileTxnSnapLog。 事务日志添加,提交,回滚,截断,委托给文件快照日志FileTxnSnapLog。 请求处理,获取节点数据,委托给有数据树DataTree。 交易快照日志FileTxnSnapLog有两部分组成一个是已提交的事务日志文件目录dataDir,快照日志文件目录snapDir组成。 事务日志txnLog对应的为FileTxnLog, 快照日志snapLog为FileSnap。
提交事务实际,实际为将文件输出流,刷新磁盘(事务日志文件目录)。 回滚事务日志,实际为重置日志流logStream为BufferedOutputStream为null。 截断日志,实际为根据事务zxid, 删除大于zxid的事务日志文件。 拍摄快照,实际为将DataTree,序列化到快照日志文件。
DataTree主要是通过节点HashMap来维护节点信息(ConcurrentHashMap<String, DataNode>())。
数据DataNode有一个字节数组(byte data[])存储数据,Set