Sqoop简介及使用
write by donaldhan, 2020-04-16 23:11引言
在业务系统中,我们将业务数据存储在关系型数据库。在业务数据累计一定量的时候,如何对这些数据进行分析,是我们需要解决的一个问题。sqoop作为连接关系型数据库和hadoop的桥梁,支持全量和增量更新的方式,将数据导入到Hadoop的BigTable体系中,比如如 Hive和HBase;以便进行分析。
目录
Sqoop的优点
- 可以高效、可控的利用资源,可以通过调整任务数来控制任务的并发度。
- 可以自动的完成数据映射和转换。由于导入数据库是有类型的,它可以自动根据数据库中的类型转换到Hadoop 中,当然用户也可以自定义它们之间的映射关系
- 支持多种数据库,如mysql,orcale等数据库
- 插拔式Connector架构, Connector是与特定数据源相关的组件, 主要负责(从特定数据源中)抽取和加载数据。用户可选择Sqoop自带的Connector, 或者数据库提供的native Connector。
sqoop工作的机制
将导入或导出命令翻译成MapReduce程序来实现在翻译出的,性能高;可以MapReduce 中主要是对InputFormat和OutputFormat进行定制.
sqoop的有sqoop1和sqoop2是两个不同的版本,它们是完全不兼容的,apache1.4.X之后的版本是1, 1.99.0之上的版本是2。
我们先来看sqoop1
Sqoop1
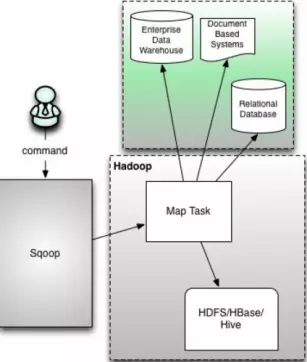
Sqoop1客户端工具 不需要启动任何服务,直接拉起MapReuce作业(实际只有Map操作), 使用方便, 只有命令行交互方式。
缺陷:
- 仅支持JDBC的Connector
- 要求依赖软件必须安装在客户端上(包括Mysql/Hadoop/Oracle客户端, JDBC驱动,数据库厂商提供的Connector等)。
- 安全性差: 需要用户提供明文密码
下面我们来体验一下数据传输。当前使用的版本为sqoop-1.4.7.tar.gz, hadoop为2.7.1, hive环境搭建见下文。
sqoop安装配置
下载sqoop-1.4.7, 并解压
donaldhan@pseduoDisHadoop:/bdp/sqoop$ ls
sqoop-1.4.7 sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz sqoop-1.4.7.tar.gz
donaldhan@pseduoDisHadoop:/bdp/sqoop$ cd sqoop-1.4.7/
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7$ pwd
/bdp/sqoop/sqoop-1.4.7
donaldhan@pseduoDisHadoop:/
配置Sqoop环境变量
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7$ cd conf/
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7/conf$ ls
oraoop-site-template.xml sqoop-env-template.sh
sqoop-env-template.cmd sqoop-site-template.xml
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7/conf$ cp sqoop-env-template.sh sqoop-env.sh
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7/conf$ vim sqoop-env.sh
具体配置如下:
# included in all the hadoop scripts with source command
# should not be executable directly
# also should not be passed any arguments, since we need original $*
# Set Hadoop-specific environment variables here.
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/bdp/hadoop/hadoop-2.7.1
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/bdp/hadoop/hadoop-2.7.1
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
export HIVE_HOME=/bdp/hive/apache-hive-2.3.4-bin
#Set the path for where zookeper config dir is
#export ZOOCFGDIR=
我们主要测试mysql到HIVE, 由于Sqoop作业用的是MR,所以需要配置Hadoop的路径。
将mysql的驱动包放到sqoop的lib目录下
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7$ cp /bdp/hive/mysql-connector-java-5.1.41.jar lib/
下载sqoop-1.4.7.jar,avro-1.8.1.jar放到sqoop的lib文件加下
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7$ ls lib/
ant-contrib-1.0b3.jar mysql-connector-java-5.1.41.jar
ant-eclipse-1.0-jvm1.2.jar sqoop-1.4.7.jar
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.
添加Sqoop路径到系统路径
export SQOOP_HOME=/bdp/sqoop/sqoop-1.4.7
export PATH=${SQOOP_HOME}/bin:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:${FLUME_HOME}/bin:${PATH}
使用以下命令
sqoop version
查看是否安装成功
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7$ sqoop version
...
20/03/18 22:33:24 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Sqoop 1.4.7
git commit id 04c9c16335b71d44fdc7d4f1deabe6f575620b94
Compiled by ec2-user on Tue Jun 12 19:50:32 UTC 2018
Sqoop的使用
查看数据库的名称:
sqoop list-databases --connect jdbc:mysql://ip:3306/ --username 用户名--password 密码
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7$ sqoop list-databases --connect jdbc:mysql://192.168.3.107:3306/ --username root --password 123456
...
20/03/18 23:01:49 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
hive_db
mysql
performance_schema
single_hive_db
test
列举出数据库中的表名:
sqoop list-tables --connect jdbc:mysql://ip:3306/数据库名称 --username 用户名 --password 密码
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7$ sqoop list-tables --connect jdbc:mysql://192.168.3.107:3306/test --username root --password 123456
...
20/03/18 23:06:09 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
20/03/18 23:06:09 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
20/03/18 23:06:09 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
blogs
comments
users
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7$
导入数据
从关系数据导出数据到HDFS,HIVE,或HBASE;
具体命令解释如下
sqoop import
--connect jdbc:mysql://ip:3306/databasename #指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
--table tablename #要读取数据库database中的表名
--username root #用户名
--password 123456 #密码
--target-dir /path #指的是HDFS中导入表的存放目录(注意:是目录)
--fields-terminated-by '\t' #设定导入数据后每个字段的分隔符,默认;分隔
--lines-terminated-by '\n' #设定导入数据后每行的分隔符
--m,--num-mappers 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据
-- where ’查询条件‘ #导入查询出来的内容,表的子集
-e,--query ‘取数sql’
--incremental append #增量导入
--check-column:column_id #指定增量导入时的参考列
--last-value:num #上一次导入column_id的最后一个值
--null-string ‘’ #导入的字段为空时,用指定的字符进行替换
--columns <col,col,col…> #筛选指定的字段
--direct #用户数据库的直接通道
--fetch-size <n> #每次抓取的记录数
注意:
–direct模式使用的是直接导入快速路径,此通道的性能可能高于使用JDBC。
对于MySQL:MySQL Direct Connector允许使用mysqldump和mysqlimport工具功能,而不是SQL选择和插入,更快地导入和导出MySQL。
准备数据
我们在mysql的test库中创建如下表
CREATE TABLE `books` (
`id` int(11) NOT NULL,
`book_name` varchar(64) DEFAULT NULL,
`book_price` decimal(10,0) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入如下数据
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`) VALUES ('1', '贫穷的本质', '39');
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`) VALUES ('2', '聪明的投资者', '42');
mysql> select * from books;
+----+--------------+------------+
| id | book_name | book_price |
+----+--------------+------------+
| 1 | 贫穷的本质 | 39 |
| 2 | 聪明的投资者 | 42 |
+----+--------------+------------+
2 rows in set
mysql>
导入mysql数据到HDFS
启动hadoop
start-dfs.sh
启动yarn
start-yarn.sh
创建hdfs目录,用户存放导出的数据
donaldhan@pseduoDisHadoop:~$ hdfs dfs -mkdir /user/sqoop
donaldhan@pseduoDisHadoop:~$ hdfs dfs -ls /user
Found 3 items
drwxr-xr-x - donaldhan supergroup 0 2019-03-24 22:08 /user/donaldhan
drwxr-xr-x - donaldhan supergroup 0 2020-02-27 22:07 /user/hive
drwxr-xr-x - donaldhan supergroup 0 2020-03-19 22:40 /user/sqoop
sqoop import --connect jdbc:mysql://192.168.3.107:3306/test --username 'root' --password '123456' --table books --target-dir /user/sqoop/books2 --fields-terminated-by '\t' --m 1
查看导入的数据文件
donaldhan@pseduoDisHadoop:~$ hdfs dfs -ls /user/sqoop/books
Found 3 items
-rw-r--r-- 1 donaldhan supergroup 0 2020-03-19 23:24 /user/sqoop/books/_SUCCESS
-rw-r--r-- 1 donaldhan supergroup 21 2020-03-19 23:24 /user/sqoop/books/part-m-00000
-rw-r--r-- 1 donaldhan supergroup 24 2020-03-19 23:24 /user/sqoop/books/part-m-00001
donaldhan@pseduoDisHadoop:~$ hdfs dfs -cat /user/sqoop/books/*01
2 聪明的投资者 42
donaldhan@pseduoDisHadoop:~$ hdfs dfs -cat /user/sqoop/books/*00
1 贫穷的本质 39
donaldhan@pseduoDisHadoop:~$
donaldhan@pseduoDisHadoop:~$ hdfs dfs -cat /user/sqoop/books/*0*
1 贫穷的本质 39
2 聪明的投资者 42
从输出日志来看每次只抓取一条记录
20/03/19 23:34:25 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `books` AS t LIMIT 1
20/03/19 23:34:25 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `books` AS t LIMIT 1
我们可以通过–fetch-size参数每次控制抓取大小
--fetch-size 2
执行的过程中,我们发现是无效的,因为被Mysql的驱动忽略
20/03/19 23:34:24 INFO manager.MySQLManager: Argument '--fetch-size 2' will probably get ignored by MySQL JDBC driver.
是否可以使用–m控制map任务数量,进而将所有的数据集中到一个文件中
--m 1
sqoop import --connect jdbc:mysql://192.168.3.107:3306/test --username 'root' --password '123456' --table books --target-dir /user/sqoop/books2 --fields-terminated-by '\t' --m 1
查看hdfs文件
donaldhan@pseduoDisHadoop:~$ hdfs dfs -ls /user/sqoop/books2
Found 2 items
-rw-r--r-- 1 donaldhan supergroup 0 2020-03-19 23:39 /user/sqoop/books2/_SUCCESS
-rw-r--r-- 1 donaldhan supergroup 45 2020-03-19 23:39 /user/sqoop/books2/part-m-00000
donaldhan@pseduoDisHadoop:~$ hdfs dfs -cat /user/sqoop/books2/*0
1 贫穷的本质 39
2 聪明的投资者 42
从hdfs目录文件来看,答案是可定的。
导入mysql数据到HIVE
HIVE相关参数
Argument Description
--hive-home <dir> Override $HIVE_HOME
--hive-import Import tables into Hive (Uses Hive’s default delimiters if none are set.)
--hive-overwrite Overwrite existing data in the Hive table.
--create-hive-table If set, then the job will fail if the target hive
table exists. By default this property is false.
--hive-table <table-name> Sets the table name to use when importing to Hive.
--hive-drop-import-delims Drops \n, \r, and \01 from string fields when importing to Hive.
--hive-delims-replacement Replace \n, \r, and \01 from string fields with user defined string when importing to Hive.
--hive-partition-key Name of a hive field to partition are sharded on
--hive-partition-value <v> String-value that serves as partition key for this imported into hive in this job.
--map-column-hive <map> Override default mapping from SQL type to Hive type for configured columns. If specify commas in this argument, use URL encoded keys and values, for example, use DECIMAL(1%2C%201) instead of DECIMAL(1, 1).
我们使用上面的数据源,
donaldhan@pseduoDisHadoop:/bdp/hive/apache-hive-2.3.4-bin/conf$ cp hive-site.xml /bdp/sqoop/sqoop-1.4.7/conf/
donaldhan@pseduoDisHadoop:/bdp/hive/apache-hive-2.3.4-bin/conf$ ls /bdp/sqoop/sqoop-1.4.7/conf/
hive-site.xml sqoop-env.sh sqoop-env-template.sh
oraoop-site-template.xml sqoop-env-template.cmd sqoop-site-template.xml
donaldhan@pseduoDisHadoop:/bdp/hive/apache-hive-2.3.4-bin/conf$
启动HIVE
hiveserver2
在启动之前,hdfs和yarn要启动。
执行如下命令
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username root \
--password 123456 \
--table books \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-import \
--hive-overwrite \
--create-hive-table \
--delete-target-dir \
--hive-database test \
--hive-table books
需要注意:Sqoop会自动创建对应的Hive表,但是hive-database 需要手动创建
donaldhan@pseduoDisHadoop:~$ beeline
beeline> !connect jdbc:hive2://pseduoDisHadoop:10000
Connecting to jdbc:hive2://pseduoDisHadoop:10000
Enter username for jdbc:hive2://pseduoDisHadoop:10000: hadoop
Enter password for jdbc:hive2://pseduoDisHadoop:10000: ******
Connected to: Apache Hive (version 2.3.4)
Driver: Hive JDBC (version 2.3.4)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://pseduoDisHadoop:10000> use test;
No rows affected (1.008 seconds)
导入成功后,查看HIVE表数据:
1: jdbc:hive2://pseduoDisHadoop:10000> show tables;
+------------------------+
| tab_name |
+------------------------+
| books |
| emp2 |
| emp3 |
| employee |
| order_multi_partition |
| order_partition |
| stu_age_partition |
| student |
| tb_array |
| tb_map |
| tb_struct |
+------------------------+
11 rows selected (0.342 seconds)
1: jdbc:hive2://pseduoDisHadoop:10000> select * from books;
+-----------+------------------+-------------------+
| books.id | books.book_name | books.book_price |
+-----------+------------------+-------------------+
| 1 | 贫穷的本质 | 39.0 |
| 2 | 聪明的投资者 | 42.0 |
+-----------+------------------+-------------------+
2 rows selected (0.681 seconds)
1: jdbc:hive2://pseduoDisHadoop:10000>
查看hive数仓的文件
donaldhan@pseduoDisHadoop:~$ hdfs dfs -ls /user/hive/warehouse/test.db/books
-rwxrwxrwx 1 donaldhan supergroup 0 2020-03-30 22:58 /user/hive/warehouse/test.db/books/_SUCCESS
-rwxrwxrwx 1 donaldhan supergroup 21 2020-03-30 22:58 /user/hive/warehouse/test.db/books/part-m-00000
-rwxrwxrwx 1 donaldhan supergroup 24 2020-03-30 22:58 /user/hive/warehouse/test.db/books/part-m-00001
donaldhan@pseduoDisHadoop:~$ hdfs dfs -cat /user/hive/warehouse/test.db/books/part-m-00000
1 贫穷的本质 39
donaldhan@pseduoDisHadoop:~$
donaldhan@pseduoDisHadoop:~$ hdfs dfs -cat /user/hive/warehouse/test.db/books/part-m-00001
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2 聪明的投资者 42
再来看先关的日志
20/03/30 22:52:37 INFO mapreduce.ImportJobBase: Publishing Hive/Hcat import job data to Listeners for table books
20/03/30 22:52:37 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `books` AS t LIMIT 1
20/03/30 22:52:37 WARN hive.TableDefWriter: Column book_price had to be cast to a less precise type in Hive
20/03/30 22:52:37 INFO hive.HiveImport: Loading uploaded data into Hive
20/03/30 22:52:37 INFO conf.HiveConf: Found configuration file file:/bdp/sqoop/sqoop-1.4.7/conf/hive-site.xml
...
0/03/30 22:59:06 INFO session.SessionState: Deleted directory: /user/hive/tmp/donaldhan/f22f2ccc-0d3a-4f35-8560-d2271cf9be58 on fs with scheme hdfs
20/03/30 22:59:06 INFO session.SessionState: Deleted directory: /bdp/hive/jobslog/donaldhan/f22f2ccc-0d3a-4f35-8560-d2271cf9be58 on fs with scheme file
20/03/30 22:59:06 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore...
20/03/30 22:59:06 INFO HiveMetaStore.audit: ugi=donaldhan ip=unknown-ip-addr cmd=Cleaning up thread local RawStore...
20/03/30 22:59:06 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore
20/03/30 22:59:06 INFO HiveMetaStore.audit: ugi=donaldhan ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore
20/03/30 22:59:06 INFO hive.HiveImport: Hive import complete.
从上面可以看出,我们在没有指定Map任务数量的情况下,每条记录实际上是一个Map任务。
下面我们使用 –m 控制map任务数量
并行控制
我们先向mysql的books、插一条数据:
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`) VALUES ('3', '去依附', '28');
使用–m控制map任务数量,进而将所有的数据集中到一个文件中,同时不再重新创建表,只需将数据表文件删除,重写文件捷库,具体如下:
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username root \
--password 123456 \
--table books \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-import \
--hive-overwrite \
--delete-target-dir \
--hive-database test \
--hive-table books \
--m 1
查看hive数据表文件:
donaldhan@pseduoDisHadoop:~$ hdfs dfs -ls /user/hive/warehouse/test.db/books
-rwxrwxrwx 1 donaldhan supergroup 0 2020-03-30 23:14 /user/hive/warehouse/test.db/books/_SUCCESS
-rwxrwxrwx 1 donaldhan supergroup 60 2020-03-30 23:14 /user/hive/warehouse/test.db/books/part-m-00000
查看hive表数据:
1: jdbc:hive2://pseduoDisHadoop:10000> select * from books;
+-----------+------------------+-------------------+
| books.id | books.book_name | books.book_price |
+-----------+------------------+-------------------+
| 1 | 贫穷的本质 | 39.0 |
| 2 | 聪明的投资者 | 42.0 |
| 3 | 去依附 | 28.0 |
+-----------+------------------+-------------------+
3 rows selected (0.404 seconds)
更多并行控制,参照 controlling_parallelism
where和query选项的使用
我们来看一下使用一下where和query选项的使用
先将HIVE BOOKS表删除
drop table books;
–where选项的使用
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username root \
--password 123456 \
--table books \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--null-string '\\N' \
--null-non-string '\\N' \
--where 'id < 3' \
--hive-import \
--target-dir /user/hive/warehouse/test.db/books \
--hive-table test.books \
--m 1
注意hive-table要加schema,不然,会到默认库中;
我们观察日志
Loading data to table test.books
20/03/31 23:04:31 INFO exec.Task: Loading data to table test.books from hdfs://pseduoDisHadoop:9000/user/hive/warehouse/test.db/books
可以发现,导入mysql到hive,实际为先将数据到hdfs文件中,然后创建hive表,将文件数据加载的hive表中。
查看表数据
0: jdbc:hive2://pseduoDisHadoop:10000> select * from books;
+-----------+------------------+-------------------+
| books.id | books.book_name | books.book_price |
+-----------+------------------+-------------------+
| 1 | 贫穷的本质 | 39.0 |
| 2 | 聪明的投资者 | 42.0 |
+-----------+------------------+-------------------+
2 rows selected (0.401 seconds)
0: jdbc:hive2://pseduoDisHadoop:10000>
我们再来看–query选项
–query选项的使用
query选项我们可以进行多表关联查询比如:
$ sqoop import \
--query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \
--split-by a.id --target-dir /user/foo/joinresults
这里我们就不在示范了。
先将HIVE BOOKS表删除
drop table books;
执行如下命令
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username root \
--password 123456 \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--null-string '\\N' \
--null-non-string '\\N' \
--query 'select * from books where $CONDITIONS' \
--split-by id \
--hive-import \
--target-dir /user/hive/warehouse/test.db/books \
--hive-table test.books \
--m 1
查看表数据
0: jdbc:hive2://pseduoDisHadoop:10000> select * from books; +———–+——————+——————-+ | books.id | books.book_name | books.book_price | +———–+——————+——————-+ | 1 | 贫穷的本质 | 39.0 | | 2 | 聪明的投资者 | 42.0 | | 3 | 去依附 | 28.0 | +———–+——————+——————-+
除了全量,筛选模式外,sqoop还可以增量导入数据。增量模式有两种模式,一种是根据给定字段,另外一个种是时间戳。
增量数据
下面我们分别来看这里两种模式
append模式
我们先向mysql的books、插一条数据:
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`) VALUES ('4', '涛动周期论', '66');
增量同步id为3之后的数据
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username root \
--password 123456 \
--table books \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-import \
--hive-database test \
--hive-table books \
--incremental append \
--check-column id \
--last-value 3 \
--m 1
控制台日志
20/03/30 23:34:39 INFO hive.HiveImport: Hive import complete.
20/03/30 23:34:39 INFO hive.HiveImport: Export directory is empty, removing it.
20/03/30 23:34:39 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments:
20/03/30 23:34:39 INFO tool.ImportTool: --incremental append
20/03/30 23:34:39 INFO tool.ImportTool: --check-column id
20/03/30 23:34:39 INFO tool.ImportTool: --last-value 4
20/03/30 23:34:39 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7/lib$
查看hive的books数据
1: jdbc:hive2://pseduoDisHadoop:10000> select * from books;
+-----------+------------------+-------------------+
| books.id | books.book_name | books.book_price |
+-----------+------------------+-------------------+
| 1 | 贫穷的本质 | 39.0 |
| 2 | 聪明的投资者 | 42.0 |
| 3 | 去依附 | 28.0 |
| 4 | 涛动周期论 | 66.0 |
+-----------+------------------+-------------------+
4 rows selected (0.481 seconds)
1: jdbc:hive2://pseduoDisHadoop:10000>
从上面可以看出,append模式主要根据某个字段进行增量同步,这个字段一般为主键比如id。
增量模式还有一种为Lastmodified,根据时间戳来增量导入。这个是否会存在,临界点的记录遗漏的问题,这个需要验证。
lastmodified模式
先将HIVE BOOKS表删除
drop table books;
修改mysql的book表接口
ALTER TABLE books ADD COLUMN `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间'
初始化数据如下:
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`, `update_time`) VALUES ('1', '贫穷的本质', '39', '2020-03-29 23:23:54');
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`, `update_time`) VALUES ('2', '聪明的投资者', '42', '2020-03-30 23:23:54');
具体如下:
mysql> select * from books;
+----+--------------+------------+---------------------+
| id | book_name | book_price | update_time |
+----+--------------+------------+---------------------+
| 1 | 贫穷的本质 | 39 | 2020-03-29 23:23:54 |
| 2 | 聪明的投资者 | 42 | 2020-03-30 23:23:54 |
+----+--------------+------------+---------------------+
4 rows in set
mysql>
执行如下语句:
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username root \
--password 123456 \
--table books \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--target-dir /user/hive/warehouse/test.db/books \
--hive-database test \
--hive-table books \
--incremental lastmodified \
--merge-key id \
--last-value "2020-03-29 23:23:54" \
--check-column update_time \
--m 1
如果我们的数据是自增不减,则可以使用创建时间,如果旧的记录会更新,可以使用 更新字段。merge-key选项,针对旧的记录我们可以,对记录进行更新。
执行命令
20/03/31 23:53:43 INFO tool.ImportTool: Final destination exists, will run merge job.
20/03/31 23:53:43 INFO tool.ImportTool: Moving data from temporary directory _sqoop/8d1ccb57b639484da8fff5341cc7ed93_books to final destination /user/hive/warehouse/test.db/books
20/03/31 23:53:43 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments:
...
20/03/31 23:53:43 INFO tool.ImportTool: Moving data from temporary directory _sqoop/8d1ccb57b639484da8fff5341cc7ed93_books to final destination /user/hive/warehouse/test.db/books
20/03/31 23:53:43 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments:
20/03/31 23:53:43 INFO tool.ImportTool: --incremental lastmodified
20/03/31 23:53:43 INFO tool.ImportTool: --check-column update_time
20/03/31 23:53:43 INFO tool.ImportTool: --last-value 2020-03-31 23:53:15.0
20/03/31 23:53:43 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create')
从日志来看,sqoop建议将任务包装为job这样我们就可以重复执行任务了。
查看hdfs文件:
donaldhan@pseduoDisHadoop:~$ hdfs dfs -ls /user/hive/warehouse/test.db/books
-rw-r--r-- 1 donaldhan supergroup 0 2020-03-31 23:53 /user/hive/warehouse/test.db/books/_SUCCESS
-rw-r--r-- 1 donaldhan supergroup 89 2020-03-31 23:53 /user/hive/warehouse/test.db/books/part-m-00000
donaldhan@pseduoDisHadoop:~$ hdfs dfs -cat /user/hive/warehouse/test.db/books/part-m-00000
1 贫穷的本质 39 2020-03-29 23:23:54.0
2 聪明的投资者 42 2020-03-31 23:52:56.0
donaldhan@pseduoDisHadoop:~$
需要注意的是,lastmodified模式是不支持hive-import的模式的,我们通过脚本将数据加载到hive表中。
新增一条记录,并修改id为2的记录;
UPDATE books SET book_price = 68 WHERE id =2;
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`, `update_time`) VALUES ('3', '去依附', '28', '2020-04-01 23:08:44');
执行如下脚本:
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username root \
--password 123456 \
--table books \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--target-dir /user/hive/warehouse/test.db/books \
--hive-database test \
--hive-table books \
--incremental lastmodified \
--merge-key id \
--last-value "2020-03-31 23:52:56" \
--check-column update_time \
--m 1
查看hdfs文件
donaldhan@pseduoDisHadoop:~$ hdfs dfs -ls /user/hive/warehouse/test.db/books
-rw-r--r-- 1 donaldhan supergroup 0 2020-04-01 23:15 /user/hive/warehouse/test.db/books/_SUCCESS
-rw-r--r-- 1 donaldhan supergroup 89 2020-04-01 23:15 /user/hive/warehouse/test.db/books/part-r-00000
donaldhan@pseduoDisHadoop:~$ hdfs dfs -cat /user/hive/warehouse/test.db/books/part-r-00000
1 贫穷的本质 39 2020-03-29 23:23:54.0
2 聪明的投资者 68 2020-04-01 23:08:44.0
3 去依附 28 2020-04-01 23:08:44.0
从上面可以看出记录2和新增记录3的数据已经同步。
我们再新增一条数据。
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`, `update_time`) VALUES ('4', '涛动周期论', '66', '2020-04-01 23:08:44');
注意这次我们新增的记录和上次同步记录的最后更新时间是相同的为2020-04-01 23:08:44。
执行如下命令
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username root \
--password 123456 \
--table books \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--target-dir /user/hive/warehouse/test.db/books \
--hive-database test \
--hive-table books \
--incremental lastmodified \
--merge-key id \
--last-value "2020-04-01 23:08:44" \
--check-column update_time \
--m 1
查看hdfs文件数据
donaldhan@pseduoDisHadoop:~$ hdfs dfs -cat /user/hive/warehouse/test.db/books/part-r-00000
1 贫穷的本质 39 2020-03-29 23:23:54.0
2 聪明的投资者 68 2020-04-01 23:08:44.0
3 去依附 28 2020-04-01 23:08:44.0
4 涛动周期论 66 2020-04-01 23:08:44.0
从数据来看,时间点重合sqoop同步数据没有问题,
从日志来看
20/04/01 23:23:34 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `books` AS t LIMIT 1
20/04/01 23:23:34 INFO tool.ImportTool: Incremental import based on column `update_time`
20/04/01 23:23:34 INFO tool.ImportTool: Lower bound value: '2020-04-01 23:08:44'
20/04/01 23:23:34 INFO tool.ImportTool: Upper bound value: '2020-04-01 23:23:35.0'
20/04/01 23:23:34 WARN manager.MySQLManager: It looks like you are importing from mysql.
没有没有根据时间戳去筛选,sqoop是如何判断记录4为新增数据的呢?我怀疑sqoop同步日志应该记录的有id相关的信息,用于处理时间戳相同的记录问题。只是猜测。
分区表
HIVE虽然没有提供分区表相关的方式,但我们通过其他方式来实现,比如说重写Sqoop的相关实现,比如说按照hive的数仓存储模式导入数据。今天我们采用第二种方式来实现分区导入;
首先创建分区表:
create table `books_partition`(
`id` int ,
`book_name` string ,
`book_price` decimal ,
`update_time` timestamp COMMENT '更新时间'
)partitioned by (day int) row format delimited fields terminated by '\t';
导入数据
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username 'root' \
--password '123456' \
--table books \
--target-dir /user/hive/warehouse/test.db/books_partition/day=20200402 \
--fields-terminated-by '\t' \
--m 1
加载分区数据
alter table books_partition add partition(day='20200402') location '/user/hive/warehouse/test.db/books_partition/day=20200402';
查询分区数据
No rows selected (0.549 seconds)
0: jdbc:hive2://pseduoDisHadoop:10000> alter table books_partition add partition(day='20200402') location '/user/hive/warehouse/test.db/books_partition/day=20200402';
No rows affected (0.726 seconds)
0: jdbc:hive2://pseduoDisHadoop:10000> select * from books_partition;
+---------------------+----------------------------+-----------------------------+------------------------------+----------------------+
| books_partition.id | books_partition.book_name | books_partition.book_price | books_partition.update_time | books_partition.day |
+---------------------+----------------------------+-----------------------------+------------------------------+----------------------+
| 1 | 贫穷的本质 | 39 | 2020-03-29 23:23:54.0 | 20200402 |
| 2 | 聪明的投资者 | 68 | 2020-04-01 23:08:44.0 | 20200402 |
| 3 | 去依附 | 28 | 2020-04-01 23:08:44.0 | 20200402 |
| 4 | 涛动周期论 | 66 | 2020-04-01 23:08:44.0 | 20200402 |
+---------------------+----------------------------+-----------------------------+------------------------------+----------------------+
4 rows selected (0.781 seconds)
0: jdbc:hive2://pseduoDisHadoop:10000>
同样的方法,将day改为20200401。
导入数据
sqoop import \
--connect jdbc:mysql://192.168.3.107:3306/test \
--username 'root' \
--password '123456' \
--table books \
--target-dir /user/hive/warehouse/test.db/books_partition/day=20200401 \
--fields-terminated-by '\t' \
--m 1
加载分区数据
alter table books_partition add partition(day='20200401') location '/user/hive/warehouse/test.db/books_partition/day=20200401';
查询数据
0: jdbc:hive2://pseduoDisHadoop:10000> select * from books_partition where day=20200401 ;
+---------------------+----------------------------+-----------------------------+------------------------------+----------------------+
| books_partition.id | books_partition.book_name | books_partition.book_price | books_partition.update_time | books_partition.day |
+---------------------+----------------------------+-----------------------------+------------------------------+----------------------+
| 1 | 贫穷的本质 | 39 | 2020-03-29 23:23:54.0 | 20200401 |
| 2 | 聪明的投资者 | 68 | 2020-04-01 23:08:44.0 | 20200401 |
| 3 | 去依附 | 28 | 2020-04-01 23:08:44.0 | 20200401 |
| 4 | 涛动周期论 | 66 | 2020-04-01 23:08:44.0 | 20200401 |
+---------------------+----------------------------+-----------------------------+------------------------------+----------------------+
4 rows selected (1.264 seconds)
0: jdbc:hive2://pseduoDisHadoop:10000>
删除分区数据的方法
ALTER TABLE books_partition DROP IF EXISTS PARTITION(day='20200401');
再次查看,数据被删除
0: jdbc:hive2://pseduoDisHadoop:10000> ALTER TABLE books_partition DROP IF EXISTS PARTITION(day='20200401');
No rows affected (1.133 seconds)
0: jdbc:hive2://pseduoDisHadoop:10000> select * from books_partition where day=20200401 ;
+---------------------+----------------------------+-----------------------------+------------------------------+----------------------+
| books_partition.id | books_partition.book_name | books_partition.book_price | books_partition.update_time | books_partition.day |
+---------------------+----------------------------+-----------------------------+------------------------------+----------------------+
+---------------------+----------------------------+-----------------------------+------------------------------+----------------------+
No rows selected (0.433 seconds)
0: jdbc:hive2://pseduoDisHadoop:10000>
除了从mysql到hive,我们还可以将hive的数据文件导出到mysql数据表中,注意目标mysql表必须
导出数据
(目标表必须在mysql数据库中已经建好,数据存放在hdfs中):
sqoop export
--connect jdbs:mysql://ip:3600/库名 #指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
--username用户名 #数据库的用户名
--password密码 #数据库的密码
--table表名 #需要导入到数据库中的表名
--export-dir导入数据的名称 #hdfs上的数据文件
--fields-terminated-by "\t" #HDFS中被导出的文件字段之间的分隔符
--lines-terminated-by "\n" #设定导入数据后每行的分隔符
--m 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据
--incremental append #增量导入
--check-column:column_id #指定增量导入时的参考列
--last-value:num #上一次导入column_id的最后一个值
--null-string '\\N' #导出的字段为空时,用指定的字符进行替换
执行如下命令
sqoop export \
--connect 'jdbc:mysql://192.168.3.107:3306/test?useUnicode=true&characterEncoding=utf-8' \
--username root \
--password 123456 \
--table books \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--null-string '\\N' \
--null-non-string '\\N' \
--export-dir /user/hive/warehouse/test.db/books_partition/day=20200402 \
--m 1
注意要加?useUnicode=true&characterEncoding=utf-8防止乱码
日志输出
20/04/02 22:21:43 INFO input.FileInputFormat: Total input paths to process : 1
20/04/02 22:21:43 INFO input.FileInputFormat: Total input paths to process : 1
20/04/02 22:21:43 INFO mapreduce.JobSubmitter: number of splits:1
20/04/02 22:21:43 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
20/04/02 22:21:43 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1585835907835_0003
...
Bytes Written=0
20/04/02 22:22:15 INFO mapreduce.ExportJobBase: Transferred 350 bytes in 33.8856 seconds (10.3289 bytes/sec)
20/04/02 22:22:15 INFO mapreduce.ExportJobBase: Exported 4 records.
donaldhan@pseduoDisHadoop:~$
查看mysql表的数据
mysql> truncate table `books`;
Query OK, 0 rows affected
mysql> select * from books;
Empty set
mysql> select * from books;
+----+--------------+------------+---------------------+
| id | book_name | book_price | update_time |
+----+--------------+------------+---------------------+
| 1 | 贫穷的本质 | 39 | 2020-03-29 23:23:54 |
| 2 | 聪明的投资者 | 68 | 2020-04-01 23:08:44 |
| 3 | 去依附 | 28 | 2020-04-01 23:08:44 |
| 4 | 涛动周期论 | 66 | 2020-04-01 23:08:44 |
+----+--------------+------------+---------------------+
4 rows in set
在我们做导入的时候,我们sqoop建议我们使用job作业,执行导入任务,以便对任务进行管理,下面我们来看一下。
job作业
创建job我们需要job存储起来,job存储方案有,通过配置–meta-connect或者在conf/sqoop-site.xml 里配置 sqoop.metastore.client.autoconnect.url 参数来指定是否使用metastore-client,具体如下:
- 方案A(推荐):不使用metastore-client
如果job信息放到 ${HOME}/.sqoop 目录下,此目录下有两个文件:
- metastore.db.properties:metastore的配置信息
- etastore.db.script:job的详细信息,通过sql语句存储
- 方案B: 不使用metastore-client
此时,job的信息会存储到配置的 autoconnect.url 的 SQOOP_SESSION 表里,但是此方案需要修改sqoop源码解决事务问题。
我们使用mysql为作为metastore
配置 cat sqoop-site.xml 文件
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7/conf$ cp sqoop-site-template.xml sqoop-site.xml
具体内容如下: 使用mysql存储sqoop metastore信息。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>sqoop.metastore.client.enable.autoconnect</name>
<value>false</value>
<description>If true, Sqoop will connect to a local metastore
for job management when no other metastore arguments are
provided.
</description>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.url</name>
<value>jdbc:mysql://mysqldb:3306/sqoop?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.username</name>
<value>root</value>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.password</name>
<value>123456</value>
</property>
</configuration>
创建表结构
CREATE TABLE SQOOP_ROOT (
version INT,
propname VARCHAR(128) NOT NULL,
propval VARCHAR(256),
CONSTRAINT SQOOP_ROOT_unq UNIQUE (version, propname)
);
插入初始化数据
INSERT INTO
SQOOP_ROOT
VALUES(
NULL,
'sqoop.hsqldb.job.storage.version',
'0'
);
命令格式如下:
sqoop job --create 作业名 -- import --connect jdbc:mysql://ip:3306/数据库 --username 用户名 --table 表名 --password 密码 --m 1 --target-dir 存放目录
即在我们导入,导出命令添加如下选项
job --create 作业名
注意– import中间是有空格的。
我们上面的增量模式任务,创建为job
sqoop job --create sync_books_append \
--meta-connect 'jdbc:mysql://mysqldb:3306/sqoop?user=root&password=123456' \
-- import \
--connect jdbc:mysql://mysqldb:3306/test \
--username root \
--password 123456 \
--table books \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-import \
--hive-database test \
--hive-table books \
--incremental append \
--check-column id \
--last-value 1 \
--m 1
查看所有job
sqoop job --list \
--meta-connect 'jdbc:mysql://mysqldb:3306/sqoop?user=root&password=123456'
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7/conf$ sqoop job --list \
> --meta-connect 'jdbc:mysql://mysqldb:3306/sqoop?user=root&password=123456'
Available jobs:
sync_books_append
查看指定的job
sqoop job --show sync_books_append \
--meta-connect 'jdbc:mysql://mysqldb:3306/sqoop?user=root&password=123456'
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7/conf$ sqoop job --show sync_books_append \
> --meta-connect 'jdbc:mysql://mysqldb:3306/sqoop?user=root&password=123456'
...
Job: sync_books_append
Tool: import
Options:
----------------------------
verbose = false
hcatalog.drop.and.create.table = false
codegen.output.delimiters.escape = 0
codegen.output.delimiters.enclose.required = false
codegen.input.delimiters.field = 0
split.limit = null
hbase.create.table = false
mainframe.input.dataset.type = p
db.require.password = false
skip.dist.cache = false
hdfs.append.dir = false
codegen.input.delimiters.escape = 0
import.fetch.size = null
accumulo.create.table = false
codegen.input.delimiters.enclose.required = false
reset.onemapper = false
codegen.output.delimiters.record = 10
import.max.inline.lob.size = 16777216
sqoop.throwOnError = false
hbase.bulk.load.enabled = false
hcatalog.create.table = false
db.clear.staging.table = false
codegen.input.delimiters.record = 0
enable.compression = false
hive.overwrite.table = false
hive.import = false
codegen.input.delimiters.enclose = 0
accumulo.batch.size = 10240000
hive.drop.delims = false
customtool.options.jsonmap = {}
codegen.output.delimiters.enclose = 0
hdfs.delete-target.dir = false
codegen.output.dir = .
codegen.auto.compile.dir = true
relaxed.isolation = false
mapreduce.num.mappers = 4
accumulo.max.latency = 5000
import.direct.split.size = 0
sqlconnection.metadata.transaction.isolation.level = 2
codegen.output.delimiters.field = 44
export.new.update = UpdateOnly
incremental.mode = None
hdfs.file.format = TextFile
sqoop.oracle.escaping.disabled = true
codegen.compile.dir = /tmp/sqoop-donaldhan/compile/d7db0462296072540d2e6f46b97642f9
direct.import = false
temporary.dirRoot = _sqoop
hive.fail.table.exists = false
db.batch = false
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-1.4.7/conf$
现在我们来执行job
执行job
准备数据,清空数据表
mysql> truncate table `books`;
Query OK, 0 rows affected
mysql> select * from books;
Empty set
插入初始化数据
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`, `update_time`) VALUES ('1', '贫穷的本质', '39', '2020-03-29 23:23:54');
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`, `update_time`) VALUES ('2', '聪明的投资者', '68', '2020-04-01 23:08:44');
sqoop job --exec sync_books_append \
--meta-connect 'jdbc:mysql://mysqldb:3306/sqoop?user=root&password=123456'
查询hive表数据
0: jdbc:hive2://pseduoDisHadoop:10000> select * from books;
+-----------+------------------+-------------------+------------------------+
| books.id | books.book_name | books.book_price | books.update_time |
+-----------+------------------+-------------------+------------------------+
| 2 | 聪明的投资者 | 68.0 | 2020-04-01 23:08:44.0 |
+-----------+------------------+-------------------+------------------------+
1 row selected (0.412 seconds)
0: jdbc:hive2://pseduoDisHadoop:10000>
只有一条数据,因为我们的id是从1开始的。
再次插入数据
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`, `update_time`) VALUES ('3', '去依附', '28', '2020-04-01 23:08:44');
INSERT INTO `test`.`books` (`id`, `book_name`, `book_price`, `update_time`) VALUES ('4', '涛动周期论', '66', '2020-04-01 23:08:44');
再次执行job
sqoop job --exec sync_books_append \
--meta-connect 'jdbc:mysql://mysqldb:3306/sqoop?user=root&password=123456'
查看hive表数据
0: jdbc:hive2://pseduoDisHadoop:10000> select * from books;
+-----------+------------------+-------------------+------------------------+
| books.id | books.book_name | books.book_price | books.update_time |
+-----------+------------------+-------------------+------------------------+
| 2 | 聪明的投资者 | 68.0 | 2020-04-01 23:08:44.0 |
| 2 | 聪明的投资者 | 68.0 | 2020-04-01 23:08:44.0 |
| 3 | 去依附 | 28.0 | 2020-04-01 23:08:44.0 |
| 4 | 涛动周期论 | 66.0 | 2020-04-01 23:08:44.0 |
+-----------+------------------+-------------------+------------------------+
4 rows selected (0.465 seconds)
为什么是4条呢,那是因为我在执行job的时候,出现了一个
ERROR tool.ImportTool: Import failed: java.io.IOException: Error communicating with database
具体见问题集,我靠使用mysql作为metastore存储,还有这个问题,有人说是sqoop创建的job会话信息的sqoop_sessions的引擎问题,由于我的数据库引擎为innodb,建议使用MyISAM引擎。这个问题导致job的信息更新失败,包括上次更新的id信息。
sqoop fails to store incremental state to the metastore
sqoop fails to store incremental state to the metastore
mysql> select * from sqoop_sessions;
+-------------------+----------------------------------------------------+------------------------------------------------------------------------------------------------------------+--------------+
| job_name | propname | propval | propclass |
+-------------------+----------------------------------------------------+------------------------------------------------------------------------------------------------------------+--------------+
| sync_books_append | accumulo.batch.size | 10240000 | SqoopOptions |
| sync_books_append | accumulo.create.table | false | SqoopOptions |
| sync_books_append | accumulo.max.latency | 5000 | SqoopOptions |
| sync_books_append | codegen.auto.compile.dir | true | SqoopOptions |
| sync_books_append | codegen.compile.dir | /tmp/sqoop-donaldhan/compile/bc0d4b0c5499abca863f92d15bf734e9 | SqoopOptions |
| sync_books_append | codegen.input.delimiters.enclose | 0 | SqoopOptions |
| sync_books_append | codegen.input.delimiters.enclose.required | false | SqoopOptions |
| sync_books_append | codegen.input.delimiters.escape | 0 | SqoopOptions |
| sync_books_append | codegen.input.delimiters.field | 0 | SqoopOptions |
| sync_books_append | codegen.input.delimiters.record | 0 | SqoopOptions |
| sync_books_append | codegen.output.delimiters.enclose | 0 | SqoopOptions |
| sync_books_append | codegen.output.delimiters.enclose.required | false | SqoopOptions |
| sync_books_append | codegen.output.delimiters.escape | 0 | SqoopOptions |
| sync_books_append | codegen.output.delimiters.field | 9 | SqoopOptions |
| sync_books_append | codegen.output.delimiters.record | 10 | SqoopOptions |
| sync_books_append | codegen.output.dir | . | SqoopOptions |
| sync_books_append | customtool.options.jsonmap | {} | SqoopOptions |
| sync_books_append | db.batch | false | SqoopOptions |
| sync_books_append | db.clear.staging.table | false | SqoopOptions |
| sync_books_append | db.connect.string | jdbc:mysql://mysqldb:3306/test | SqoopOptions |
| sync_books_append | db.require.password | true | SqoopOptions |
| sync_books_append | db.table | books | SqoopOptions |
| sync_books_append | db.username | root | SqoopOptions |
| sync_books_append | direct.import | false | SqoopOptions |
| sync_books_append | enable.compression | false | SqoopOptions |
| sync_books_append | export.new.update | UpdateOnly | SqoopOptions |
| sync_books_append | hbase.bulk.load.enabled | false | SqoopOptions |
| sync_books_append | hbase.create.table | false | SqoopOptions |
| sync_books_append | hcatalog.create.table | false | SqoopOptions |
| sync_books_append | hcatalog.drop.and.create.table | false | SqoopOptions |
| sync_books_append | hdfs.append.dir | true | SqoopOptions |
| sync_books_append | hdfs.delete-target.dir | false | SqoopOptions |
| sync_books_append | hdfs.file.format | TextFile | SqoopOptions |
| sync_books_append | hive.database.name | test | SqoopOptions |
| sync_books_append | hive.drop.delims | false | SqoopOptions |
| sync_books_append | hive.fail.table.exists | false | SqoopOptions |
| sync_books_append | hive.import | true | SqoopOptions |
| sync_books_append | hive.overwrite.table | false | SqoopOptions |
| sync_books_append | hive.table.name | books | SqoopOptions |
| sync_books_append | import.direct.split.size | 0 | SqoopOptions |
| sync_books_append | import.fetch.size | null | SqoopOptions |
| sync_books_append | import.max.inline.lob.size | 16777216 | SqoopOptions |
| sync_books_append | incremental.col | id | SqoopOptions |
| sync_books_append | incremental.last.value | 1 | SqoopOptions |
| sync_books_append | incremental.mode | AppendRows | SqoopOptions |
| sync_books_append | mainframe.input.dataset.type | p | SqoopOptions |
| sync_books_append | mapreduce.client.genericoptionsparser.used | true | config |
| sync_books_append | mapreduce.num.mappers | 1 | SqoopOptions |
| sync_books_append | relaxed.isolation | false | SqoopOptions |
| sync_books_append | reset.onemapper | false | SqoopOptions |
| sync_books_append | skip.dist.cache | false | SqoopOptions |
| sync_books_append | split.limit | null | SqoopOptions |
| sync_books_append | sqlconnection.metadata.transaction.isolation.level | 2 | SqoopOptions |
| sync_books_append | sqoop.job.storage.implementations | com.cloudera.sqoop.metastore.hsqldb.HsqldbJobStorage,com.cloudera.sqoop.metastore.hsqldb.AutoHsqldbStorage | config |
| sync_books_append | sqoop.oracle.escaping.disabled | true | SqoopOptions |
| sync_books_append | sqoop.property.set.id | 0 | schema |
| sync_books_append | sqoop.throwOnError | false | SqoopOptions |
| sync_books_append | sqoop.tool | import | schema |
| sync_books_append | temporary.dirRoot | _sqoop | SqoopOptions |
| sync_books_append | verbose | false | SqoopOptions |
+-------------------+----------------------------------------------------+------------------------------------------------------------------------------------------------------------+--------------+
60 rows in set
mysql>
从session的信息我们可以看出,最后的id为1,所以2记录数据重复插入到hive数据表。
incremental.last.value | 1
具体解决办法,可以使用hsqldb作为metastore, 同时将mysql中,
删除job
sqoop job --delete sync_books_append \
--meta-connect 'jdbc:mysql://mysqldb:3306/sqoop?user=root&password=123456'
从上面可以看出,使用sqoop存储job时,建议使用hsqldb作为存储,兼容性更多,功能更完善。
sqoop1的命令行模式,很容易出问题,有条件建议使用Sqoop2。
我们来简单看一下sqoop2.
Sqoop2
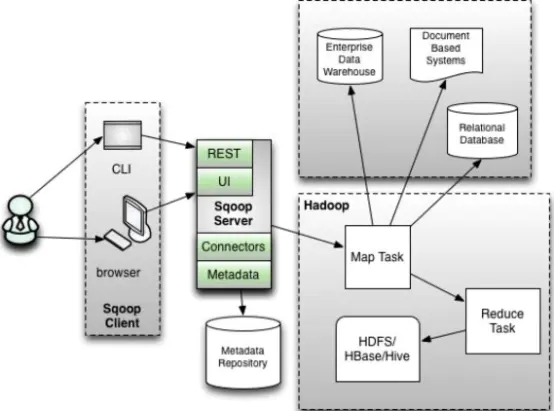
sqoop2引入了Sqoop Server端, 形成服务端-客户端,Connector集成到Server端,轻量客户端。
Sqoop Client
用户交互的方式:命令行(CLI) 和浏览器两种方式
Sqoop Server:
- Connector
- Partitioner 数据切片
- Extractor 数据抽取 Map操作
- Loader 读取Extractor输出的数据,Reduce操作
-
Metadata Sqoop中的元信息,次啊用轻量级数据库Apache Derby, 也可以替换为Mysql
-
RESTful和HTTP Server 客户端对接请求
总结
将mysql导入到hdfs,可以使用–m控制map任务数量,进而将所有的数据集中到一个文件中;导入mysql到hive,实际为先将数据到hdfs文件中,然后创建hive表,将文件数据加载的hive表中。除了全量,筛选模式外,sqoop还可以增量导入数据。增量模式有两种模式,一种是根据给定字段append模式,另外一个种是时间戳增量更新模式lastmodified模式。append模式主要根据某个字段进行增量同步,这个字段一般为主键比如id。针对,如果我们的数据是自增不减,则可以使用创建时间,如果旧的记录会更新,可以使用更新字段。merge-key选项,针对旧的记录我们可以,对记录进行更新。lastmodified模式是不支持hive-import的模式的,我们通过脚本将数据加载到hive表中。 使用sqoop存储job时,建议使用hsqldb作为存储,兼容性更多,功能更完善。sqoop1的命令行模式,很容易出问题,有条件建议使用Sqoop2。
附
参考文献
sqoop
sqoop github
真正了解sqoop的一切
Sqoop简介
Sqoop1.4.7UserGuide
Sqoop使用笔记
分区表的折衷方法
sqoop 导入hive分区表的方法
Sqoop 数据导入多分区Hive解决方法
Sqoop-从hive导出分区表到MySQL
sqoop使用mysql做为metastore sqoop1使用metastore保存job
HSQLDB快速指南
HSQLDB使用
HSQLDB 安装与使用
HSQLDB Client 命令行访问
hsqldb metatore 存储方式配置
首先配置sqoop-site.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>sqoop.jobbase.serialize.sqoopoptions</name>
<value>true</value>
<description>If true, then all options will be serialized into job.xml
</description>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.username</name>
<value>SA</value>
<description>The username to bind to the metastore.
</description>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.password</name>
<value></value>
<description>The password to bind to the metastore.
</description>
</property>
<!-- sqoop执行时会让输入密码,这里value改成true后,会自动保存密码,这样就可以做定时任务(job自动执行) -->
<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
<description>If true, allow saved passwords in the metastore.
</description>
</property>
<!-- 本地存储方式hslqdb -->
<property>
<name>sqoop.metastore.server.location</name>
<value>/bdp/sqoop/sqoop-metastore/shared.db</value>
<description>Path to the shared metastore database files.
If this is not set, it will be placed in ~/.sqoop/.
</description>
</property>
<property>
<name>sqoop.metastore.server.port</name>
<value>16000</value>
<description>Port that this metastore should listen on.
</description>
</property>
<!-- 创建job可以不用指定meta-connect -->
<property>
<name>sqoop.metastore.client.autoconnect.url</name>
<value>jdbc:hsqldb:hsql://127.0.0.1:16000/sqoop</value>
</property>
</configuration>
创建对应的log文件夹: 启动metastore
sqoop metastore &
启动完在创建了一个sqoop-metastore文件夹,存放hsqldb相关的数据
donaldhan@pseduoDisHadoop:/bdp/sqoop$ cd sqoop-metastore/
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-metastore$ ls
shared.db.lck shared.db.properties shared.db.tmp
shared.db.log shared.db.script
注意这个有很多问题,想尝试的可以趟一趟,(~)
另外一个种metastore启动方式
启动metastore
start-metastore.sh -p sqoop-metastore -l /bdp/sqoop/log
关闭metastore
stop-metastore.sh -p sqoop-metastore
问题集
ERROR tool.ImportTool: Import failed: java.io.IOException: Error communicating with database
20/04/16 22:26:47 ERROR tool.ImportTool: Import failed: java.io.IOException: Error communicating with database
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.createInternal(HsqldbJobStorage.java:426)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.update(HsqldbJobStorage.java:445)
at org.apache.sqoop.tool.ImportTool.saveIncrementalState(ImportTool.java:171)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:541)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:628)
at org.apache.sqoop.tool.JobTool.execJob(JobTool.java:243)
at org.apache.sqoop.tool.JobTool.run(JobTool.java:298)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transaction
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:425)
at com.mysql.jdbc.Util.getInstance(Util.java:408)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:951)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3973)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3909)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2527)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2680)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2501)
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:1858)
at com.mysql.jdbc.PreparedStatement.executeUpdateInternal(PreparedStatement.java:2079)
at com.mysql.jdbc.PreparedStatement.executeUpdateInternal(PreparedStatement.java:2013)
at com.mysql.jdbc.PreparedStatement.executeLargeUpdate(PreparedStatement.java:5104)
at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1998)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.setV0Property(HsqldbJobStorage.java:707)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.createInternal(HsqldbJobStorage.java:391)
... 12 more
我使用的mysql作为metastore存储,为什么回报这个错误。
sqoop fails to store incremental state to the metastore
sqoop fails to store incremental state to the metastore
ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.NullPointerException
20/04/16 22:02:50 ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.NullPointerException
java.lang.NullPointerException
at org.json.JSONObject.<init>(JSONObject.java:144)
at org.apache.sqoop.util.SqoopJsonUtil.getJsonStringforMap(SqoopJsonUtil.java:43)
at org.apache.sqoop.SqoopOptions.writeProperties(SqoopOptions.java:785)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.createInternal(HsqldbJobStorage.java:399)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.create(HsqldbJobStorage.java:379)
at org.apache.sqoop.tool.JobTool.createJob(JobTool.java:181)
at org.apache.sqoop.tool.JobTool.run(JobTool.java:294)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
Avoid NullPointerException due to different JSONObject library in classpath
Got exception running Sqoop java.lang.NullPointerException at org
注意这个问题是官方的一个bug,可以通过引入jar来解决,具体需要的jar为java-json.jar,java-json-schema.jar,然后放到sqoop-1.4.7/lib下即可。
Error: Could not find or load main class org.apache.sqoop.Sqoop
Error: Could not find or load main class org.apache.sqoop.Sqoop
问题原因:缺失sqoop-1.4.7.jar包,下载放到lib即可。
Sqoop找不到主类 Error: Could not find or load main class org.apache.sqoop.Sqoop
运行sqoop 报 Could not find or load main class org.apache.sqoop.Sqoop
Caused by: java.lang.ClassNotFoundException: org.apache.avro.
Caused by: java.lang.ClassNotFoundException: org.apache.avro.LogicalType
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 10 more
问题原因:缺失avro-1.8.1.jar包,下载放到lib即可。
Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/commons/lang3/StringUtils
缺失commons-lang3-3.8.1.jar,下载放到lib即可。
ERROR tool.ImportTool: Import failed: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
20/03/23 22:47:05 ERROR tool.ImportTool: Import failed: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
问题原因:无法找到HiveConf;
解决方式,声明HIVE LIB环境变量,具体如下
export HADOOP_CLASSPATH=${HADOOP_HOME}/lib/*:${HIVE_HOME}/lib/*
sqoop:【error】mysql导出数据到hive报错HiveConfig:无法加载org.apache.hadoop.hive.conf.HiveConf。确保HIVE_CONF_DIR设置正确
Import failed: java.io.IOException: Hive CliDriver exited with status=40000
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1708)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:83)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:133)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3600)
at org.apache.ha
20/03/23 22:57:11 ERROR tool.ImportTool: Import failed: java.io.IOException: Hive CliDriver exited with status=40000
at org.apache.sqoop.hive.HiveImport.executeScript(HiveImport.java:355)
at org.apache.sqoop.hive.HiveImport.importTable(HiveImport.java:241)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:537)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:628)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
问题原因分析
20/03/25 23:15:07 INFO session.SessionState: Created HDFS directory: /tmp/hive/donaldhan/99d95a39-1d2c-47f3-8e4b-33523b300727
20/03/25 23:15:07 INFO session.SessionState: Created local directory: /tmp/donaldhan/99d95a39-1d2c-47f3-8e4b-33523b300727
20/03/25 23:15:07 INFO session.SessionState: Created HDFS directory: /tmp/hive/donaldhan/99d95a39-1d2c-47f3-8e4b-33523b300727/_tmp_space.db
从上面可以看出创建的是临时文件。
再看相关的日志:
WARN DataNucleus.Query: Query for candidates of org.apache.hadoop.hive.metastore.model.MDatabase and subclasses resulted in no possible candidates
Required table missing : "DBS" in Catalog "" Schema "". DataNucleus requires this table to perform its persistence operations. Either your MetaData is incorrect, or you need to enable "datanucleus.schema.autoCreateTables"
org.datanucleus.store.rdbms.exceptions.MissingTableException: Required table missing : "DBS" in Catalog "" Schema "". DataNucleus requires this table to perform its persistence operations. Either your MetaData is incorrect, or you need to enable "datanucleus.schema.autoCreateTables"
at org.datanucleus.store.rdbms.table.AbstractTable.exists(AbstractTable.java:606)
...
java.sql.SQLSyntaxErrorException: Table/View 'DBS' does not exist.
at org.apache.derby.impl.jdbc.SQLExceptionFactory40.getSQLException(Unknown Source)
at org.apache.derby.impl.jdbc.Util.generateCsSQLException(Unknown Source)
at org.apache.derby.impl.jdbc.TransactionResourceImpl.wrapInSQLException(Unknown Source)
找不到对应的table和Schema
20/03/25 23:15:24 ERROR metastore.RetryingHMSHandler: HMSHandler Fatal error: MetaException(message:Version information not found in metastore. )
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:7564)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:7542)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.RawStoreProxy.invoke(RawStoreProxy.java:101)
20/03/25 23:15:24 WARN metadata.Hive: Failed to register all functions.
java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1708)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:83)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:133)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3600)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3652)
...
Caused by: MetaException(message:Version information not found in metastore. )
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:7564)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:7542)
尝试修改HIVE配置文件,添加如下属性
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<property>
<name>datanucleus.schema.autoCreateTables</name>
<value>true</value>
</property>
没有作用
donaldhan@pseduoDisHadoop:/bdp/hive/apache-hive-2.3.4-bin/conf$ cp hive-site.xml /bdp/sqoop/sqoop-1.4.7/conf/
donaldhan@pseduoDisHadoop:/bdp/hive/apache-hive-2.3.4-bin/conf$ ls /bdp/sqoop/sqoop-1.4.7/conf/
hive-site.xml sqoop-env.sh sqoop-env-template.sh
oraoop-site-template.xml sqoop-env-template.cmd sqoop-site-template.xml
donaldhan@pseduoDisHadoop:/bdp/hive/apache-hive-2.3.4-bin/conf$
Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
hive常见问题解决干货大全
在hue 使用oozie sqoop 从mysql 导入hive 失败
Sqoop importing is failing with ERROR com.jolbox.bonecp.BoneCP - Unable to start/stop JMX
Import failed: java.io.IOException: Hive CliDriver exited with status=1
20/03/30 22:52:56 ERROR tool.ImportTool: Import failed: java.io.IOException: Hive CliDriver exited with status=1
at org.apache.sqoop.hive.HiveImport.executeScript(HiveImport.java:355)
at org.apache.sqoop.hive.HiveImport.importTable(HiveImport.java:241)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:537)
20/03/30 22:52:55 ERROR exec.DDLTask: org.apache.hadoop.hive.ql.metadata.HiveException: AlreadyExistsException(message:Table books already exists)
问题原因,表已存在,将表删除即可。
1: jdbc:hive2://pseduoDisHadoop:10000> drop table books;
No rows affected (5.203 seconds)
Unknown incremental import mode: append. Use ‘append’ or ‘lastmodified’.
Unknown incremental import mode: append. Use 'append' or 'lastmodified'.
Try --help for usage instructions.
问题原因,无法识别导入模式,检查命令的拼写是否存在错误。
Cannot specify –query and –table together.
20/03/31 22:35:25 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
Cannot specify --query and --table together.
Try --help for usage instructions.
问题原因, –query and –table不能一起使用
Query [select * from books where id < 3] must contain ‘$CONDITIONS’ in WHERE clause.
20/03/31 22:41:10 ERROR tool.ImportTool: Import failed: java.io.IOException: Query [select * from books where id < 3] must contain ‘$CONDITIONS’ in WHERE clause. at org.apache.sqoop.manager.ConnManager.getColumnTypes(ConnManager.java:332)
问题原因:–query选项必须包含$CONDITIONS,与–split-by结合使用。
–incremental lastmodified option for hive imports is not supported
--incremental lastmodified 和 --hive-import 竟然不能同时使用。把 lastmodified 改成 append 后就可以运行了。 或者将--hive-import去掉;
sqoop-incremental-import-to-hive-table
ERROR tool.JobTool: I/O error performing job operation: java.io.IOException: Could not load HSQLDB JDBC driver
问题原因,sqoop metastore没有启动。
ERROR tool.JobTool: I/O error performing job operation: java.io.IOException: Exception creating SQL connection
ERROR tool.JobTool: I/O error performing job operation: java.io.IOException: Exception creating SQL connection
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.init(HsqldbJobStorage.java:216)
问题原因,sqoop metastore没有启动。
Exception in thread “main” java.lang.NoClassDefFoundError: org/hsqldb/Server
Exception in thread "main" java.lang.NoClassDefFoundError: org/hsqldb/Server
at org.apache.sqoop.metastore.hsqldb.HsqldbMetaStore.start(HsqldbMetaStore.java:111)
缺少hsqldb jar包,下载即可。 Sqoop metastore cannot be started due to missing hsqldb jar file
I/O error performing job operation: java.io.IOException: Invalid metadata version.
20/04/06 00:03:39 WARN hsqldb.HsqldbJobStorage: Could not interpret as a number: null
20/04/06 00:03:39 ERROR hsqldb.HsqldbJobStorage: Can not interpret metadata schema
20/04/06 00:03:39 ERROR hsqldb.HsqldbJobStorage: The metadata schema version is null
20/04/06 00:03:39 ERROR hsqldb.HsqldbJobStorage: The highest version supported is 0
20/04/06 00:03:39 ERROR hsqldb.HsqldbJobStorage: To use this version of Sqoop, you must downgrade your metadata schema.
20/04/06 00:03:39 ERROR tool.JobTool: I/O error performing job operation: java.io.IOException: Invalid metadata version.
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.init(HsqldbJobStorage.java:202)
at org.apache.sqoop.metastore.hsqldb.AutoHsqldbStorage.open(AutoHsqldbStorage.java:112)
at org.apache.sqoop.tool.JobTool.run(JobTool.java:289)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
GRANT DBA TO SA
SET SCHEMA SYSTEM_LOBS
INSERT INTO BLOCKS VALUES(0,2147483647,0)
FileNotFoundException: /bdp/sqoop/sqoop-metastore/shared.db.lck (Not a directory
FATAL [HSQLDB Server @769e7ee8] hsqldb.db.HSQLDB714AEF38D6.ENGINE - could not reopen database
org.hsqldb.HsqlException: Database lock acquisition failure: lockFile: org.hsqldb.persist.LockFile@4976de43[file =/bdp/sqoop/sqoop-metastore/shared.db.lck, exists=false, locked=false, valid=false, ] method: openRAF reason: java.io.FileNotFoundException: /bdp/sqoop/sqoop-metastore/shared.db.lck (Not a directory
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-metastore$ ls
shared.db.lck shared.db.properties shared.db.tmp
shared.db.log shared.db.script
donaldhan@pseduoDisHadoop:/bdp/sqoop/sqoop-metastore$ tail -n 5 shared.db.script
GRANT USAGE ON DOMAIN INFORMATION_SCHEMA.YES_OR_NO TO PUBLIC
GRANT USAGE ON DOMAIN INFORMATION_SCHEMA.TIME_STAMP TO PUBLIC
GRANT USAGE ON DOMAIN INFORMATION_SCHEMA.CARDINAL_NUMBER TO PUBLIC
GRANT USAGE ON DOMAIN INFORMATION_SCHEMA.CHARACTER_DATA TO PUBLIC
GRANT DBA TO SA
sqoop metastore &
上述启动方式,会默认在当前目录先创建一个sqoop-metastore,及hsqldb的数据库数据文件。
使用
start-metastore.sh -p sqoop-metastore -l /bdp/sqoop/log
启动metastore, 没有对应的sqoop-metastore文件夹,或者/bdp/sqoop/sqoop-metastore/shared.db.lck文件缺失。
Caused by: java.sql.SQLInvalidAuthorizationSpecException: invalid authorization specification
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
20/04/15 23:09:33 ERROR tool.JobTool: I/O error performing job operation: java.io.IOException: Exception creating SQL connection
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.init(HsqldbJobStorage.java:216)
at org.apache.sqoop.metastore.hsqldb.AutoHsqldbStorage.open(AutoHsqldbStorage.java:112)
at org.apache.sqoop.tool.JobTool.run(JobTool.java:289)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
Caused by: java.sql.SQLInvalidAuthorizationSpecException: invalid authorization specification: SA
at org.hsqldb.jdbc.JDBCUtil.sqlException(Unknown Source)
at org.hsqldb.jdbc.JDBCUtil.sqlException(Unknown Source)
at org.hsqldb.jdbc.JDBCConnection.<init>(Unknown Source)
at org.hsqldb.jdbc.JDBCDriver.getConnection(Unknown Source)
这个hsqldb中job存储版本的问题,参考文中的方式初始化数据库;
Caused by: org.hsqldb.HsqlException: Parameter not set
20/04/15 23:20:57 ERROR tool.JobTool: I/O error performing job operation: java.io.IOException: Exception creating SQL connection
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.init(HsqldbJobStorage.java:216)
at org.apache.sqoop.metastore.hsqldb.AutoHsqldbStorage.open(AutoHsqldbStorage.java:112)
at org.apache.sqoop.tool.JobTool.run(JobTool.java:289)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
Caused by: java.sql.SQLException: Parameter not set
at org.hsqldb.jdbc.JDBCUtil.sqlException(Unknown Source)
at org.hsqldb.jdbc.JDBCUtil.sqlException(Unknown Source)
at org.hsqldb.jdbc.JDBCUtil.sqlException(Unknown Source)
at org.hsqldb.jdbc.JDBCPreparedStatement.checkParametersSet(Unknown Source)
at org.hsqldb.jdbc.JDBCPreparedStatement.fetchResult(Unknown Source)
at org.hsqldb.jdbc.JDBCPreparedStatement.executeUpdate(Unknown Source)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.setRootProperty(HsqldbJobStorage.java:618)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.createRootTable(HsqldbJobStorage.java:531)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.init(HsqldbJobStorage.java:185)
... 8 more
Caused by: org.hsqldb.HsqlException: Parameter not set
at org.hsqldb.error.Error.error(Unknown Source)
问题原因,命令行中的– import之间没有空格